Wafer Map Anomaly Classification with Cosmos Reason 1
Authors: Anita Chiu • Tim Lin Organization: NVIDIA
Overview
| Model | Workload | Use Case |
|---|---|---|
| Cosmos Reason 1 | Post-training | Wafer Map Anomaly Classification |
In the heart of every modern electronic device lies a silicon chip, the product of a manufacturing process so intricate that even a microscopic defect can mean the difference between success and failure. As semiconductor devices become more complex, reliably detecting and classifying defects has become a critical bottleneck for the industry.
Wafer maps provide a spatial view of defect distributions across an entire wafer. Historically, chipmakers have relied on convolutional neural networks (CNNs) to automate defect classification (ADC). But as the scale and variety of manufacturing requirements increase, CNNs are reaching their limits—requiring vast labeled datasets and frequent retraining.
Supervised Fine-Tuning (SFT) is used to improve the accuracy of a pre-trained model by teaching it to follow specific instructions or understand new tasks using labeled examples. While a base model learns general patterns from large, diverse data, SFT aligns the model to specific tasks with desired outputs by showing clear input–output pairs. Using domain-specific data is essential—it embeds the specialized vocabulary, visual patterns, and reasoning needed for real-world scenarios.
In this recipe, we show how to fine-tune Cosmos Reason 1-7B, a NVIDIA reasoning vision language model (VLM) using SFT to understand wafer map defect patterns. VLMs fuse advanced image recognition with natural language processing to reason over multimodal inputs.
Before fine-tuning the model, we first review its zero-shot performance on wafer map anomaly classification. The model correctly identifies some defect patterns but struggles to distinguish between visually similar classes.

After being fine-tuned, Cosmos Reason can reach classification accuracy of 96.8%. This recipe will walk you through the workflow to fine-tune Cosmos Reason 1—from data preparation and supervised fine-tuning on the prepared dataset to evaluation.
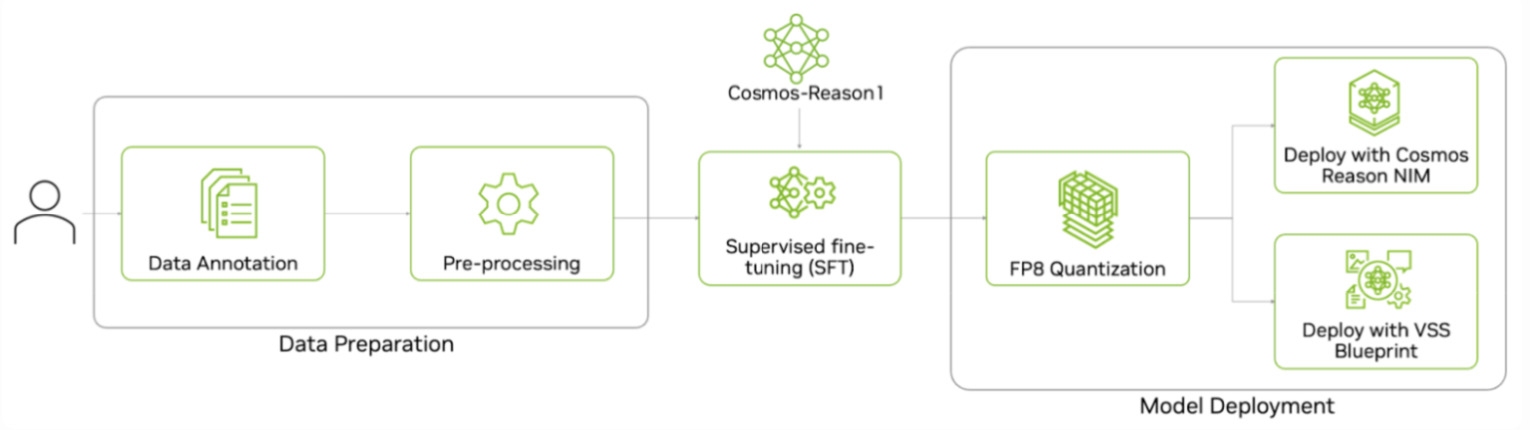
Data Preparation
Dataset Overview
Here is the end-to-end workflow for fine-tuning Cosmos Reason 1, covering data preparation, supervised training, and inference. In this example, we use the WM-811k Wafer Map dataset from Mir Lab. The model is fine-tuned on eight wafer defect categories, using curated image–question–answer pairs. The defect classes include center, donut, edge-loc, edge-ring, loc, near-full, random, and scratch, as illustrated below.
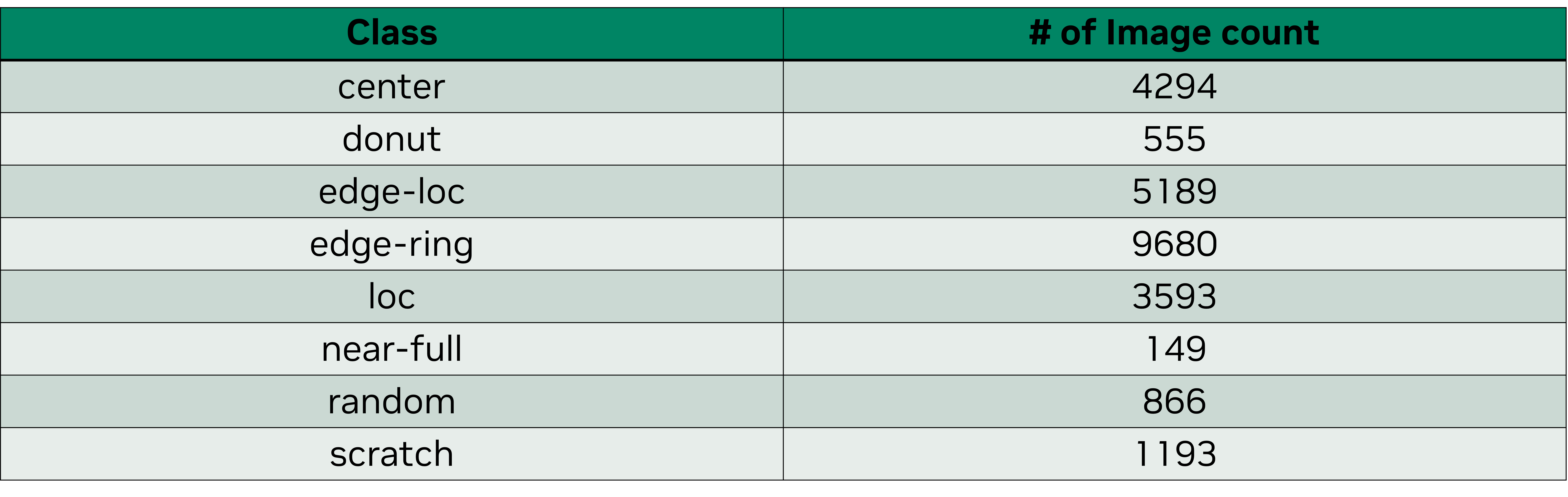
 The table below shows the original distribution of the dataset. To create a more balanced and uniform training set, we randomly sampled 800 wafer-map images—100 images per class—for the fine-tuning process.
The table below shows the original distribution of the dataset. To create a more balanced and uniform training set, we randomly sampled 800 wafer-map images—100 images per class—for the fine-tuning process.
Note: This example is intended to demonstrate post-training on Cosmos Reason 1. The dataset used in this experiment is governed by the terms specified for the WM-811k Wafer Map dataset.
Data Preprocessing
To create the sampled subset, first download the WM811K.pkl file and use the ./scripts/get_data_WM811K.py script provided in the cookbook:
After generating the sampled dataset, run ./scripts/create_annotation.py to produce the annotation JSON file used for SFT:
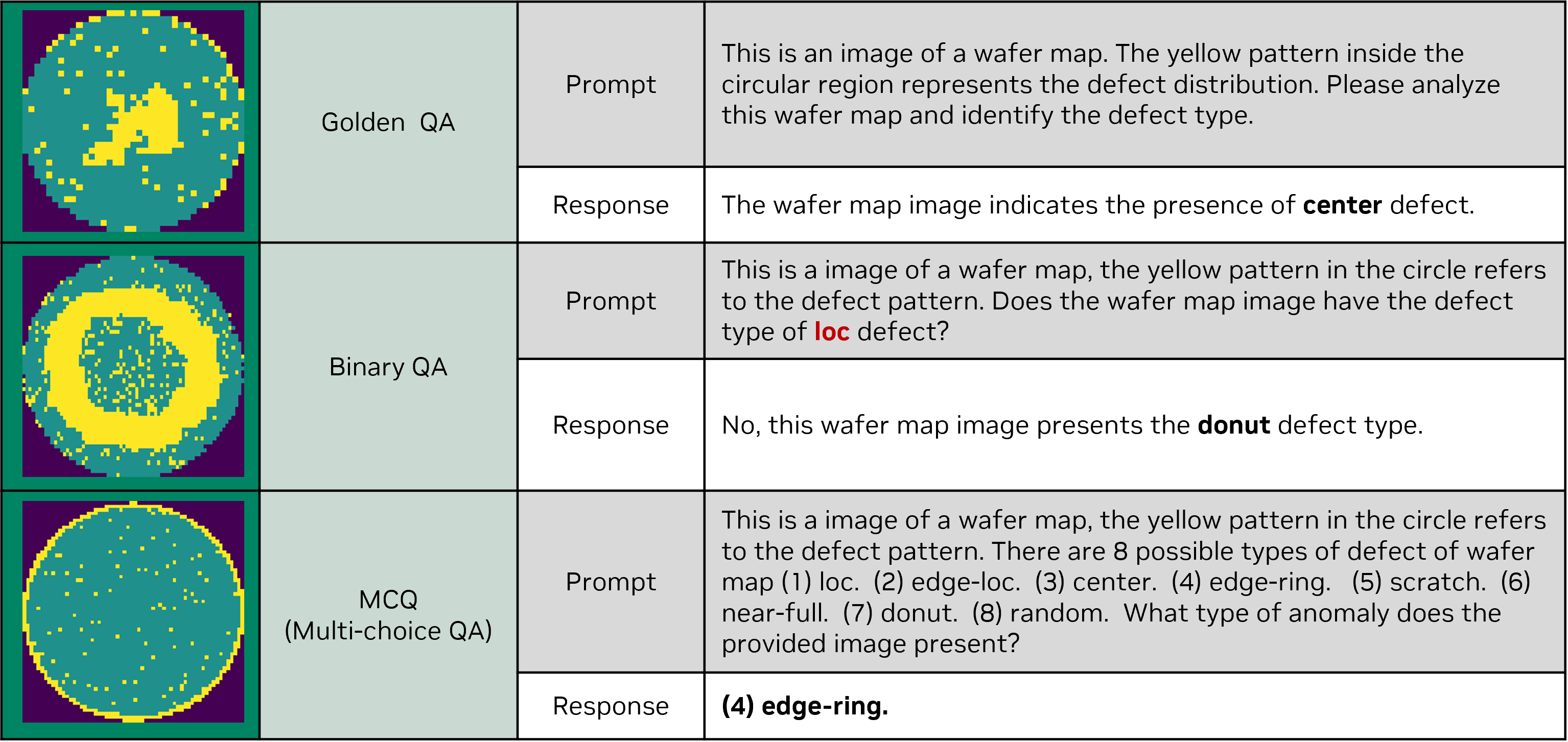
Below are sample images and textual descriptions of wafer-map defects from the dataset. The images and labels are provided courtesy of Mir Lab, and the annotations were produced by NVIDIA.
Post-Training with Supervised Fine-Tuning (SFT)
Environment Setup
Before running this recipe, complete the environment configuration: Setup and System Requirements.
Prepare SFT Dataset (LLaVA Format)
- Navigate to the LLaVA post-training example: Create dataset directory and move the provided WM811K dataset into the directory
Create & Activate the SFT Virtual Environment
- From inside
examples/post_training_llava/:
This sets up the dedicated environment for post-training.
Configure SFT Training
- Edit the configuration file
cosmos-reason1/examples/post_training_llava/configs/sft.toml. - Update:
- annotation_path → path to your JSON/JSONL dataset
- media_path → folder containing images or extracted video frames
Example:
redis = "12800"
[custom.dataset]
annotation_path = "./data/sft/WM811K_data/wafer_anolamy_small_0115.json"
media_path = "./data/sft/WM811K_data/train"
system_prompt = ""
[train]
output_dir = "outputs/sft"
compile = false
train_batch_per_replica = 32
[policy]
model_name_or_path = "nvidia/Cosmos-Reason1-7B"
model_max_length = 4096
[logging]
logger = ['console', 'wandb']
project_name = "cosmos_reason1"
experiment_name = "post_training_llava/sft"
[train.train_policy]
type = "sft"
mini_batch = 4
[train.ckpt]
enable_checkpoint = true
[policy.parallelism]
tp_size = 1
cp_size = 1
dp_shard_size = 4
pp_size = 1
The config file is also provided in the cookbook at ./configs/sft.toml
Run the SFT Training Script
- From
cosmos-reason1/examples/post_training_llava/, run:
This will launch the SFT training pipeline using Cosmos-RL’s orchestration.
Model Evaluation
After training, we evaluate the model on the validation split of the WM811K subset from our curated dataset. The evaluation is based on the defect label predicted in the model’s response. We report accuracy, recall, precision, and F1-score as our metrics.
Results
Quantitative Results
We begin by reviewing the quantitative results of our classification experiment on the WM811K dataset. The test set includes eight wafer defect categories—center, donut, edge-loc, edge-ring, loc, near-full, random, and scratch—with 20 test images per category.
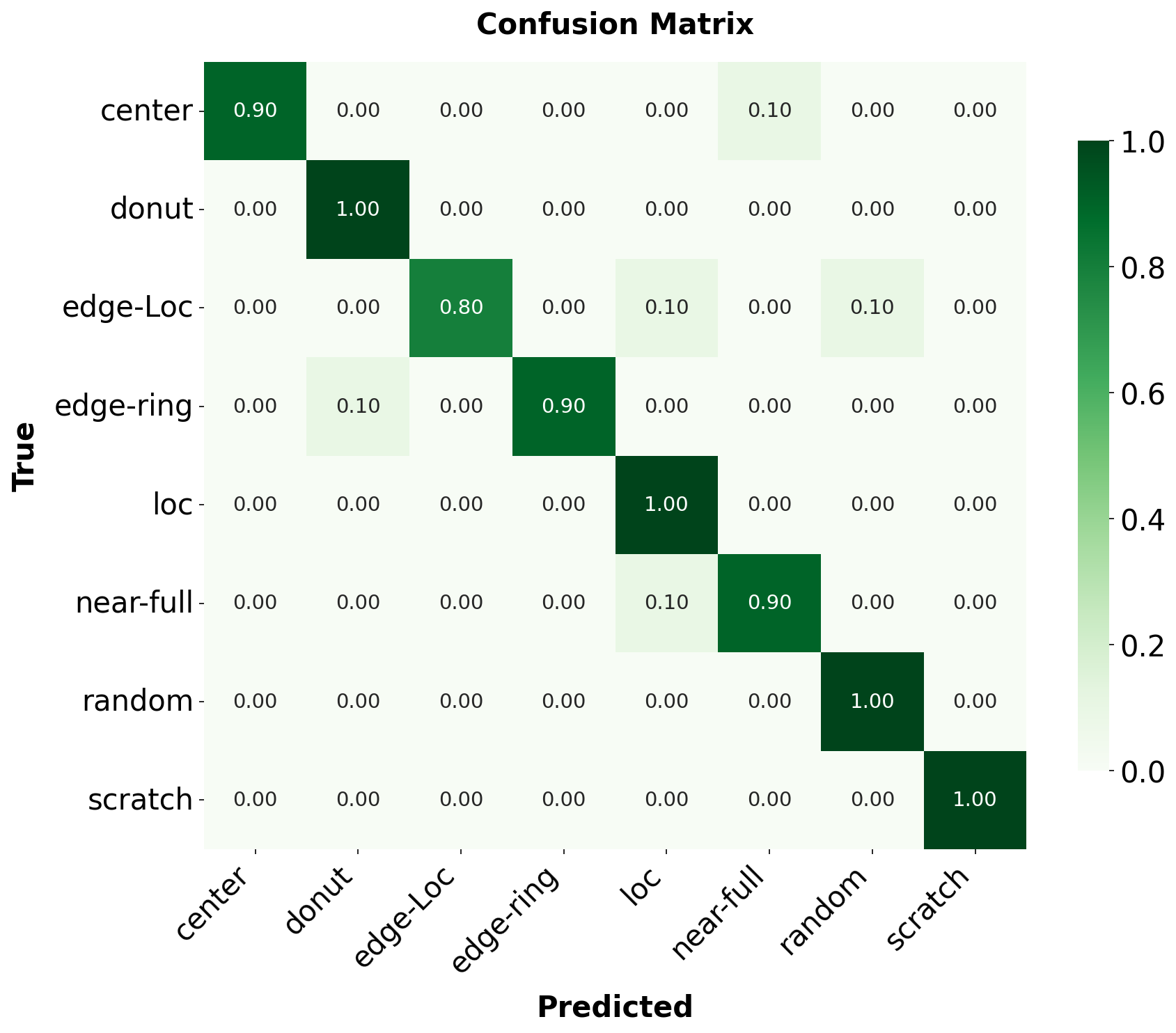
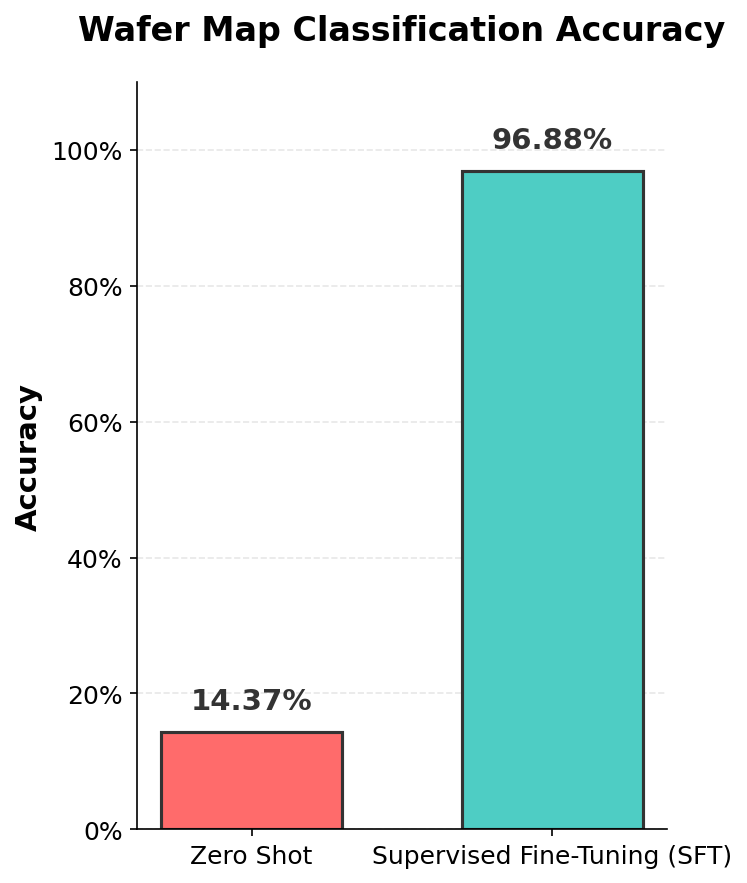
Above are the confusion matrix and the bar chart of the evaluation results between zero-shot and fine-tuned. After fine-tuning, the classification accuracy reached 96.8%, whereas the zero-shot accuracy was only 14.37%. This demonstrates that supervised fine-tuning greatly improved the model’s performance on the anomaly classification task.

Conclusion
Supervised fine-tuning of Cosmos Reason 1 on wafer map anomaly data boosts accuracy from zero-shot levels to over 96% on anomaly classification tasks. Key insights include:
- Importance of specialized data: Using specialized datasets leads to substantial performance improvements.
- Training efficiency: Training with 4K vision tokens per frame converged twice as fast as 8K tokens, achieving similar accuracy.
This methodology can be applied to any industrial anomaly classification task by substituting the relevant dataset.
Document Information
Publication Date: December 12, 2025
Citation
If you use this recipe or reference this work, please cite it as:
@misc{cosmos_cookbook_wafer_map_anomaly_2025,
title={Wafer Map Anomaly Classification with Cosmos Reason 1},
author={Chiu, Anita and Lin, Tim},
year={2025},
month={December},
howpublished={\url{https://nvidia-cosmos.github.io/cosmos-cookbook/recipes/post_training/reason1/wafermap_classification/post_training.html}},
note={NVIDIA Cosmos Cookbook}
}
Suggested text citation:
Anita Chiu, & Tim Lin (2025). Wafer Map Anomaly Classification with Cosmos Reason 1. In NVIDIA Cosmos Cookbook. Accessible at https://nvidia-cosmos.github.io/cosmos-cookbook/recipes/post_training/reason1/wafermap_classification/post_training.html