Intelligent Transportation Post-Training with Cosmos Reason 1
Authors: Paris Zhang • Chintan Shah • Tomasz Kornuta Organization: NVIDIA
| Model | Workload | Use Case |
|---|---|---|
| Cosmos Reason 1 | Post-training | Intelligent transportation scene understanding |
Overview
Supervised Fine-Tuning (SFT) is used to improve the accuracy of a pre-trained model by teaching it to follow specific instructions or understand new tasks using labeled examples. While a base model learns general patterns from large, diverse data, SFT aligns the model to specific tasks with desired outputs by showing clear input–output pairs. Using domain-specific data is essential—it embeds the specialized vocabulary, visual patterns, and reasoning needed for real-world scenarios. In this recipe, we show how to fine-tune the Cosmos Reason 1-7B model to understand the world from a traffic point of view - scene understanding, road attributes, and pedestrian situation.
Before fine-tuning the model, let's review the zero-shot performance of the model. The model spots some of the content correctly while identifying one of the pedestrians crossing the road incorrectly.

Here’s the end-to-end workflow to fine-tune Cosmos Reason 1—from data preparation and supervised fine-tuning on the prepared dataset to quantizing and deploying the model for inference.
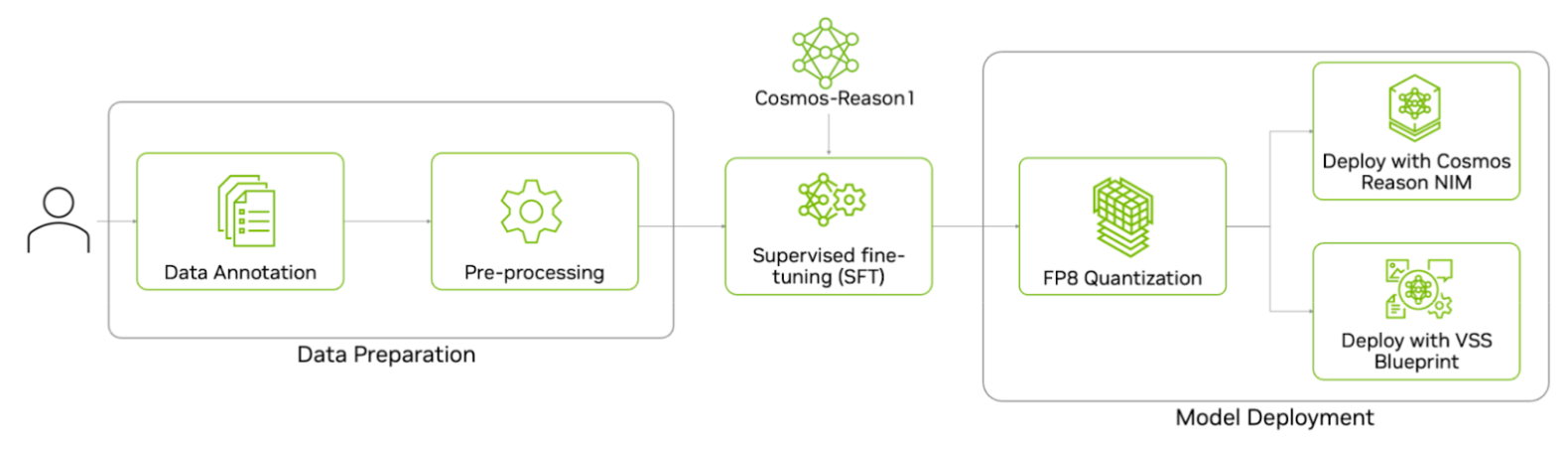
Data Preparation
For this experiment, we used the WovenTraffic Safety (WTS) Dataset from Woven by Toyota, Inc.. This is a real-world pedestrian-centric traffic video dataset featuring 255 traffic scenarios, including staged pedestrian-related accidents across 1.2k video segments. It provides detailed textual descriptions of pedestrian and vehicle behavior, bounding box annotations, and traffic Visual Question Answering (VQA) with multiple-choice questions (MCQ).
Note: The goal of this example is to demonstrate post-training on Cosmos-Reason 1. The dataset used in this experiment is governed by the terms specified in the WTS DATASET Terms of Use.
Here are examples of the video clips and textual descriptions of the pedestrian from the dataset. The images and text are courtesy of Woven by Toyota, Inc.

For this experiment, we fine-tune the Cosmos Reason 1 model on the Environment VQA subset of the WTS dataset. The subset contains 341 videos with 5k MCQ question-answer pairs. The average video length is about 75 seconds.
Data Pre-processing
We performed the following steps to pre-process the dataset:
-
Download the dataset from the WTS Dataset homepage. This dataset is owned and managed by “Woven by Toyota”. To use this dataset for your own applications, you must request access directly from the “Woven by Toyota” organization.
-
Pre-process the VQA annotations into Llava dataset format. This format is a JSON-based structure commonly used for visual SFT on VLMs, including Llava and Qwen-VL families. Each entry contains an id, a reference to the media (video or image), and a conversation between query from a human and the expected answer from the VLM model. Here is an example:
{
"id": "question_id",
"video": "path/to/video.mp4",
"conversations": [
{
"from": "human",
"value": "<video>\n What is the weather in the video?"
},
{
"from": "gpt",
"value": "The weather in the video is sunny."
}
]
}
To pre-process the dataset, run the following command:
# From scripts/examples/reason1/intelligent-transportation directory
python data_preprocess.py --data_path /path/to/WTS/folder
Post-Training with Supervised Fine-Tuning (SFT)
After preprocessing, the WTS dataset is in Llava dataset format and ready for training. To launch training, we follow the default cosmos-rl training command in Cosmos Reason 1 Post-Training Llava Example:
# From scripts/examples/reason1/intelligent-transportation directory
cosmos-rl --config sft_config.toml custom_sft.py
Hyperparameter optimization
For this SFT experiment, we updated the default configuration in the post-training Llava example for Cosmos Reason 1. Here are the key updates that optimize this experiment on 8 A100.
Training Configuration
[custom.dataset]
annotation_path = "/path/to/WTS/environment_mcq_llava_train.py"
media_path = "/path/to/WTS/videos/train"
system_prompt = "You are a helpful assistant that can answer questions about a street-view CCTV footage."
[custom.vision]
fps = 1
max_pixels = 81920
[train]
output_dir = "outputs/wts_environment_mcq"
optm_warmup_steps = 0
train_batch_per_replica = 16
enable_validation = false
[policy]
model_name_or_path = "nvidia/Cosmos-Reason1-7B"
model_max_length = 32768
[logging]
logger = ['console', 'wandb']
project_name = "cosmos_reason1"
experiment_name = "post_training/wts_environment_mcq"
[train.train_policy]
type = "sft"
mini_batch = 1
dataset.test_size = 0
[train.ckpt]
enable_checkpoint = true
[policy.parallelism]
tp_size = 1
cp_size = 1
dp_shard_size = 8
pp_size = 1
Ablation Study
We ablated the training with two common configurations for different frame resolutions:
- Max pixels 81,920 per frame: This translates to roughly 4k total vision tokens, according to the average WTS video length. The calculation is provided below.
- Total pixels 6,422,528: This translates to a total of 8k vision tokens. The calculation is provided below.
Calculation for max_pixels 81,920 to 4k total vision tokens
- Frame Calculation:
On average, our training video is about 75 seconds long. With 1 fps, it is:
75 seconds * 1 fps = 75 frames per video - Frame Grouping:
According to the Qwen2.5-VL paper (the backbone model of Cosmos-Reason 1), the model groups every two consecutive frames as a single unit input to the language model:
75 frames / 2 = 38 frame pairs per video - Tokens per Frame:
The Qwen2.5-VL model uses a vision transformer that processes images in patches. Each token corresponds to a
28 x 28 = 784pixel area, so we set max pixels per frame as 81,920 pixels:81,920 pixels/frame / 784 pixels/token ≈ 104 tokens/frame - Total Vision Tokens:
Multiply the number of frame groups by the tokens per frame:
38 frame groups × 104 tokens/group = 3,952 tokens
Calculation for total_pixels 6,422,528 to 8k total vision tokens
As noted above, based on the Qwen2.5-VL model architecture, each vision token represents a 28 x 28 = 784 pixel area, so we set total_pixels as 6,422,528:
6,422,528 pixels / 784 pixels/token = 8,192 tokens
Model Evaluation
After training, we evaluate the model on the validation set of the Environment VQA subset of the WTS dataset. The evaluation script below will save the model responses and accuracy score in the results directory.
We then updated the eval_config.yaml with the path to the post-trained model and the validation set.
# From scripts/examples/reason1/intelligent-transportation directory
python evaluate.py --config eval_config.yaml
Results
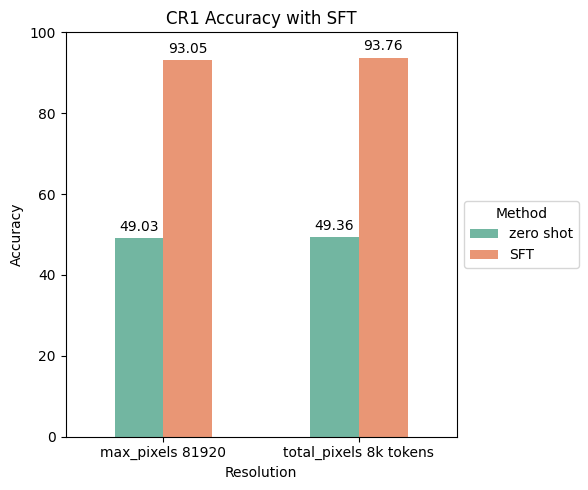
Quantitative Results
First, let's review the quantitative results on the environment VQA subset of the WTS dataset for each experiment: one with 81,920 pixels/frame (4K visual tokens) and another with 8K visual tokens. This is a collection of multiple choice questions (MCQ) on traffic and pedestrian videos. Overall, we see the accuracy jump to over 90 for both experiments. There is not a lot of delta in training accuracy between the two experiments, and 4K visual tokens will converge faster and provide faster inference times.
Training Time
We ran all the experiments on 1 node (8 GPUs) of A100. The table below captures the training time for the two different settings with one training epoch. Both were run with a 1 FPS sampling rate. As expected with only 81,920 pixels/frame (4K vision tokens), the model converged in roughly half the time as 8K vision tokens. In summary, you can train a very accurate model using this amount of data in an hour or less.
| Method | FPS & Resolution | Training Time (on 8 A100s) |
|---|---|---|
| SFT | Fps 1, max pixels/frame 81920 | 35m |
| SFT | Fps 1, total pixels 8k vision tokens | 1h 3m |
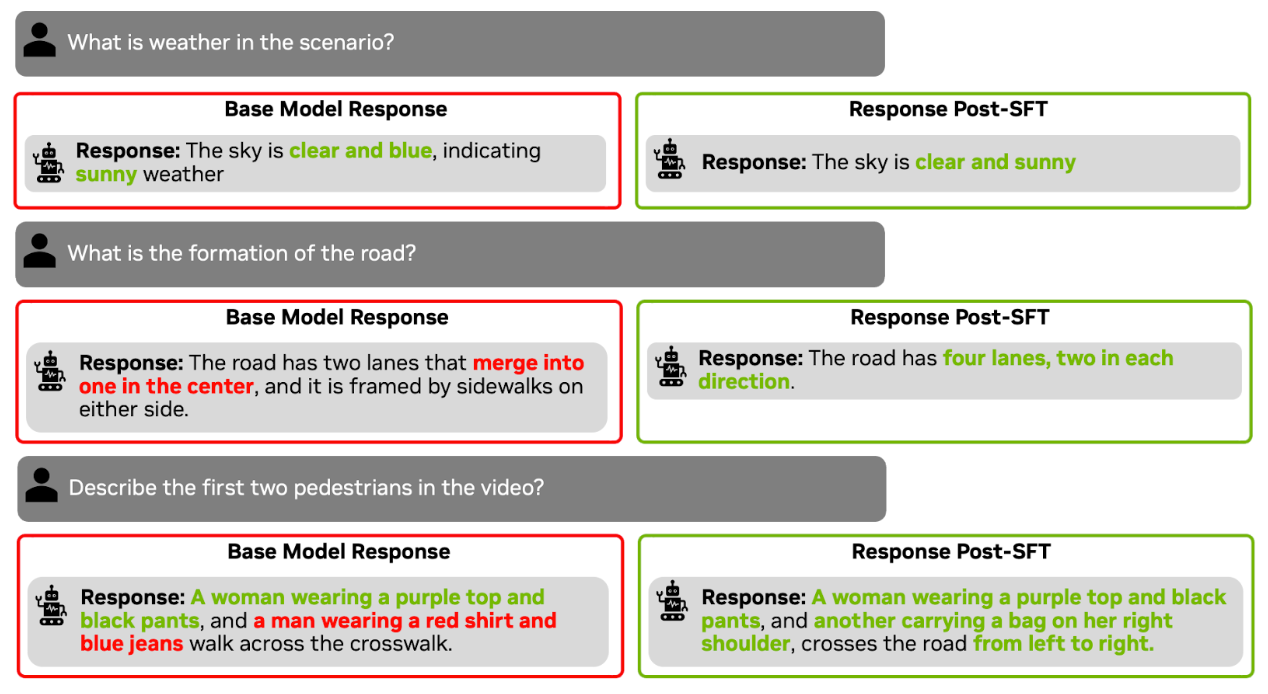
Qualitative Results
After SFT training with multiple choice questions (MCQ), the model achieves a significant accuracy improvement on the validation set MCQs on WTS videos. Additionally, the model is also able to answer open-ended questions more accurately than zero shot on external videos. Below is a qualitative comparison of open-ended questions on an unseen video outside of WTS dataset.
Model Deployment
The last step is to deploy the trained model for inference. You can deploy it using either an NVIDIA optimized NIM or through the VSS blueprint, or you can deploy it in your own application. Before deployment, we will first quantize the LLM portion of the VLM to FP8 for faster inference.
FP8 Quantization
The script to quantize the model to FP8 is provided in the NVIDIA Cosmos Reason 1 repo.
-
Clone the Cosmos Reason 1 repo.
-
To run post-training quantization (PTQ), install the following dependencies:
-
Run the
quantize_fp8.pyscript.
python ./scripts/quantize_fp8.py --model_id 'nvidia/Cosmos-Reason-1-7B' --save_dir 'Cosmos-Reason-1-7B-W8A8-FP8'
Before deploying the quantized model for inference, we ran an evaluation on the model for accuracy and ensured quantization doesn’t introduce any accuracy regression.
Deploy on NVIDIA NIM
NVIDIA NIM™ provides containers to self-host GPU-accelerated inferencing microservices for pre-trained and customized AI models across cloud instances, data centers, and RTX™ AI PCs and workstations, with industry-standard APIs for simple integration into AI applications.
To deploy a post-trained checkpoint, go to the fine-tune-model section in NIM documentation. Go to "Cosmos Reason 1-7B" tab. NIM will automatically serve an optimized vLLM engine for this model. The model needs to be in the Huggingface checkpoint or quantized checkpoint.
export CUSTOM_WEIGHTS=/path/to/customized/reason1
docker run -it --rm --name=cosmos-reason1-7b \
--gpus all \
--shm-size=32GB \
-e NIM_MODEL_NAME=$CUSTOM_WEIGHTS \
-e NIM_SERVED_MODEL_NAME="cosmos-reason1-7b" \
-v $CUSTOM_WEIGHTS:$CUSTOM_WEIGHTS \
-u $(id -u) \
-p 8000:8000 \
$NIM_IMAGE
Deploy with NVIDIA VSS Blueprint
The VSS (Video Search and Summarization) Blueprint leverages both Vision-Language Models (VLM) and Large Language Models (LLM) to generate captions, answer questions, and summarize video content, enabling rapid search and understanding of videos on NVIDIA hardware.
By default, VSS is configured to use base Cosmos Reason 1-7B as the default VLM. Deployment instructions for VSS are available in its official documentation. VSS supports two primary deployment methods: Docker Compose and Helm charts.
For Docker Compose deployment, navigate to the Configure the VLM section under “Plug-and-Play Guide (Docker Compose Deployment)” to integrate a custom fine-tuned Cosmos-Reason 1 checkpoint.
export VLM_MODEL_TO_USE=cosmos-reason1
export MODEL_PATH=</path/to/local/cosmos-reason1-checkpoint>
export MODEL_ROOT_DIR=<MODEL_ROOT_DIR_ON_HOST>
Similarly for Helm Chart deployment, navigate to the Configure the VLM section under “Plug-and-Play Guide (Helm Deployment)”.
vss:
applicationSpecs:
vss-deployment:
containers:
vss:
env:
- name: VLM_MODEL_TO_USE
value: cosmos-reason1
- name: MODEL_PATH
value: "/tmp/cosmos-reason1"
extraPodVolumes:
- name: local-cosmos-reason1-checkpoint
hostPath:
path: </path/to/local/cosmos-reason1-checkpoint>
extraPodVolumeMounts:
- name: local-cosmos-reason1-checkpoint
mountPath: /tmp/cosmos-reason1
Conclusion
Supervised Fine-Tuning Cosmos Reason 1 on traffic-specific data boosts accuracy from zero-shot levels to over 90% on traffic VQA tasks. Key insights include the following:
- Domain data matters: Specialized datasets drive substantial performance gains.
- Efficient training: 4K vision tokens per frame converged twice as fast as 8K, with similar accuracy.
- Seamless deployment: Workflow supports quantization and deployment via NIM or VSS.
This methodology can be applied to any physical AI domain by substituting relevant datasets.
Document Information
Publication Date: October 10, 2025
Citation
If you use this recipe or reference this work, please cite it as:
@misc{cosmos_cookbook_its_post_training_2025,
title={Intelligent Transportation Post-Training with Cosmos Reason 1},
author={Zhang, Paris and Shah, Chintan and Kornuta, Tomasz},
year={2025},
month={October},
howpublished={\url{https://nvidia-cosmos.github.io/cosmos-cookbook/recipes/post_training/reason1/intelligent-transportation/post_training.html}},
note={NVIDIA Cosmos Cookbook}
}
Suggested text citation:
Paris Zhang, Chintan Shah, & Tomasz Kornuta (2025). Intelligent Transportation Post-Training with Cosmos Reason 1. In NVIDIA Cosmos Cookbook. Accessible at https://nvidia-cosmos.github.io/cosmos-cookbook/recipes/post_training/reason1/intelligent-transportation/post_training.html