Post-train Cosmos Reason 2 for Autonomous Vehicle Video Captioning and VQA
NVIDIA: Jingyi Jin*, Shun Zhang*, Xiaodong Yang
Uber: Joseph Wang
* Equal contribution
| Model | Workload | Use Case |
|---|---|---|
| Cosmos Reason 2 | Post-training | AV video captioning and visual question answering |
Overview
This recipe is a collaboration between Uber and NVIDIA to improve Cosmos Reason 2 as a video captioner for autonomous vehicle (AV) applications. Caption quality is assessed through Visual Question Answering (VQA) accuracy. Cosmos Reason 2 is NVIDIA's latest vision-language model with strong video understanding and spatial reasoning capabilities. This recipe demonstrates how to adapt it for domain-specific AV captioning through targeted post-training.
The Challenge
Uber's dedicated AV data-collection fleet captures massive volumes of video data daily. The challenge is transforming this raw data into a curated, searchable asset—enabling teams to locate anomaly scenes, edge cases, and safety-critical situations for training and testing. High-quality video captioning is essential: accurate captions allow raw video to be organized into searchable databases for scenario retrieval, model training, and safety validation. Video-language models like Cosmos Reason 2 can serve as powerful auto-labelers, dramatically reducing cost compared to manual annotation.
However, VLMs often produce captions that lack critical details needed for AV applications. While VLMs can capture basic scene elements, they frequently miss key information about ego vehicle behavior, precise signage text, vehicle descriptions (colors, types), infrastructure details, and spatial context critical for AV training. Additionally, VLMs may hallucinate details that are not present in the video, which can be problematic for safety-critical applications. This recipe demonstrates how targeted post-training can improve upon these limitations.
Recipe Workflow
This recipe fine-tunes Cosmos Reason 2 to produce domain-specific AV captions. The evaluation benchmark was designed using Uber's real-world use cases. The workflow:
- Benchmark Definition: Build an evaluation benchmark guided by Uber's operational requirements.
- Zero-Shot Evaluation: Evaluate baseline models (Cosmos Reason 1 and 2) to understand gaps and compare generational improvements.
- Data Curation: Curate training data based on identified gaps.
- Post-Training (SFT): Fine-tune Cosmos Reason 2 on the curated dataset.
- Re-Evaluation: Measure improvements using VQA accuracy.
- Conclusion: Summarize findings, key takeaways, and recommendations for production deployment.
1. Benchmark Definition
The evaluation benchmark was designed with input from Uber's real-world operations, ensuring metrics and scenarios reflect genuine operational requirements.
Requirements
The benchmark evaluates VLM capabilities across six key areas critical to autonomous vehicle understanding:
| Category | Scope |
|---|---|
| Scene Description | Environment type (urban/rural/highway), buildings, road structures, time of day, weather, lane count, road condition, signs, crosswalks, intersections, traffic controls, land use, special zones |
| Key Objects | Vehicle types and sizes, emergency vehicles, parked vehicles, vehicle colors, traffic lights, construction objects, public transit, sign colors, commercial vehicles, road hazards |
| Characters & Interactions | Pedestrian presence and location, cyclists, workers, children, pedestrian grouping, carried items, position relative to ego |
| Actions & Motion | Lead vehicle behavior, other vehicle turns and lane changes, pedestrian crossing, traffic flow, loading/unloading, unusual maneuvers, pedestrian activities |
| Ego Vehicle Behavior | Primary maneuver, turn type, stopping behavior, speed behavior, lane changes, following behavior, unsafe behaviors, intersection behavior |
| Spatial & Temporal | Nearest vehicle position, road direction, distance visibility, event sequence, video start/end states, element absence |
These capability areas were identified through collaboration with Uber's AV operations team based on real-world operational needs for scenario retrieval, safety validation, and model training data curation.
Evaluation Dataset
The evaluation dataset consists of ~500 front dash cam videos with diverse driving scenarios, each paired with detailed human annotations:
| Specification | Details |
|---|---|
| Video Count | ~500 front dash cam videos |
| Duration | 30 seconds per video |
| Resolution | 1936 × 1220 @ 30 fps |
| Scenarios | Diversified (urban, suburban, highway, varied weather/lighting) |
| Human Annotations | Perception, action classification, danger level assessment, and spatial-temporal relationships |
These human annotations serve as ground truth for evaluating model outputs across all evaluation methods.
Evaluation Methods
We employ three complementary evaluation methods to comprehensively assess model performance:
1.1 BLEU Score
BLEU (Bilingual Evaluation Understudy) measures n-gram precision between generated captions and reference annotations. For each video, the model-generated caption is compared against the human-annotated caption as the reference. Scores range from 0 to 1, where higher indicates better lexical overlap with the ground truth. Fast and reproducible, but does not capture semantic similarity—two captions with identical meaning but different wording may score poorly.
1.2 MCQ-based VQA
Multiple-choice VQA provides objective accuracy metrics. We constructed a pool of 50 questions across 6 categories, each with 4 answer choices: Scene Description (13), Key Objects (10), Actions & Motion (8), Ego Vehicle Behavior (7), Characters & Interactions (6), and Spatial & Temporal (6).
Construction: For each video, we select 12 questions—6 required questions covering core capabilities, and 6 randomly sampled from the remaining pool. Each question is answered in parallel by: (1) an LLM (GPT5.1) using only the human annotations, and (2) a VLM (GPT5.1) using the video content. When answers contradict, human reviewers either correct the ground truth or remove ambiguous questions. This process yields ~5,000 verified question-answer pairs.
1.3 LingoQA Benchmark
A standardized external benchmark for AV visual question answering 1. The full benchmark contains 28K video scenarios with 419K annotations, evaluated using Lingo-Judge (0.95 Spearman correlation with human evaluations). For our evaluation, we selected 100 videos and a subset of questions most relevant to our use case. This external benchmark validates that improvements generalize beyond our internal benchmark.
2. Zero-Shot Evaluation
We evaluate Cosmos Reason 2 and Qwen3-VL models in zero-shot mode to establish baselines and select a base model for post-training. Based on this evaluation, we select Cosmos Reason 2-8B as the base model due to its strong reasoning capabilities, competitive VQA performance, and alignment with NVIDIA's Cosmos ecosystem.
Note: BLEU scores for the base model are presented in Section 5: Re-Evaluation, where we compare zero-shot vs. fine-tuned performance.
2.1 MCQ-based VQA Results
The following table shows the performance of different models on the AV-VQA benchmark:
| Category | Cosmos Reason 2-2B | Cosmos Reason 2-8B | Qwen3-VL-2B | Qwen3-VL-8B |
|---|---|---|---|---|
| Actions & Motion | 71.0% | 79.6% | 59.4% | 79.6% |
| Characters & Interactions | 83.6% | 89.5% | 82.9% | 88.2% |
| Ego Behavior | 76.4% | 75.7% | 58.8% | 72.3% |
| Key Objects | 76.6% | 86.1% | 63.4% | 81.8% |
| Scene Description | 80.1% | 81.7% | 66.6% | 80.2% |
| Spatial Temporal | 57.0% | 65.1% | 51.9% | 58.8% |
| Overall | 74.7% | 80.1% | 64.1% | 77.5% |
Evaluation Details:
- Total predictions: 5,050
- Videos evaluated: 455
- Parseable rate: 100.0%
- Mean per-video accuracy: 74.6% (±12.6%) for Reason 2-2B, 80.1% (±12.9%) for Reason 2-8B, 64.1% (±14.5%) for Qwen3-VL-2B, 77.4% (±12.8%) for Qwen3-VL-8B
2.2 LingoQA Benchmark Results
| Model | LingoQA Score |
|---|---|
| Cosmos Reason 2-2B | 0.640 |
| Cosmos Reason 2-8B | 0.632 |
| Qwen3-VL-2B-Instruct | 0.608 |
| Qwen3-VL-8B-Instruct | 0.694 |
Summary
Model Selection: Cosmos Reason 2-8B was chosen as the base model for post-training.
The zero-shot evaluation reveals capability gaps—particularly in Spatial-Temporal reasoning (65.1%) and Ego Behavior (75.7%)—that inform the data curation strategy for post-training.
3. Data Curation
Based on gaps identified in zero-shot evaluation, we curate training data from three sources:
Source 1: Human-Annotated Captions [2]
About 12K video clips (20 seconds each) with high-quality human annotations. Each caption is organized into three components: (1) General description—ego-vehicle behavior, environmental conditions (scene type, time of day, weather, road conditions), and key road users/infrastructure (vehicles, pedestrians, cyclists, traffic lights, signs); (2) Driving difficulty—scenario complexity based on driver attention required and rarity/risk; (3) Notice—salient events such as traffic signals, road user interactions, and abnormal behaviors.
Source 2: Computer Vision Auto-Captioned Data [3]
Designed for VLA modeling, this labeling framework encodes causal structure through reasoning traces and driving decisions. High-level driving decisions map directly to ego-vehicle trajectories, with reasoning traces capturing only causal factors motivating each decision. We use keyframe-based labeling centered on meta-action transitions.
This source includes ~11K human-labeled and ~1.1M auto-labeled samples. Human annotators identify critical components, filter invalid data (illegal/unsafe behaviors), and produce reasoning traces linking causal factors to decisions. Auto-labeling uses VLMs to generate structured annotations (driving decision, critical components, causal explanation), incorporating video inputs plus auxiliary signals (trajectory, dynamic states, meta-actions).
Source 3: Reasoning SFT Data
Targets AV reasoning capability for Cosmos Reason 2. Previously curated for prediction/navigation tasks, this dataset extends perceptual information with explicit reasoning traces. Each annotation follows a structured JSON format: (1) General description—ego driving behavior, rationale, environmental context, and critical objects; (2) Driving difficulty explanation—scenario complexity assessment; (3) Timestamped notices—noteworthy events with temporal annotations (e.g., "Between 8.3s–11.3s: Approaching level crossing"). Emphasizes causal reasoning by linking observations to driving decisions.
Example Annotations
Human Annotation Example:
Click to expand annotation JSON
{
"weather": "Partly cloudy",
"lighting": "Daytime (diffused light)",
"road_conditions": "Dry, clean asphalt",
"traffic_light": "No traffic light is visible.",
"traffic_sign": "Parking signs are visible on the right side of the street.",
"additional_traffic_rules": "Pedestrian crosswalk markings are visible ahead at the intersection.",
"road_type": "Local street – low‑speed, mixed residential/commercial access.",
"junction_type": "Straight segment - uninterrupted roadway with no intersections or turns",
"lane_type": "A single unidirectional lane.",
"additional_map_rules": "Parking line markings are visible on the right side of the road.",
"interactive_expanded_metaaction": ["Vehicle following"],
"noninteractive_expanded_metaaction": null,
"safety_analysis": "The ego vehicle is driving straight on a local street having a single unidirectional lane. The ego vehicle drives on the left side of the road, following a gray SUV, and on the right side of the road, many vehicles are parked on the parking line markings. Parking signs on the right side of the road and pedestrian crosswalk markings are visible ahead at the intersection.",
"driving_difficulty": 2,
"rule_violation": "False",
"interesting_scenario": "True",
"critical_object": [
{
"box": {"x1": 2755.46, "y1": 748.28, "x2": 2858.53, "y2": 825.2},
"box_time": 2,
"critical_reasoning": "The ego vehicle is following the gray SUV, and thus it is a critical object.",
"object_type": "Vehicles - Light trucks & SUVs"
}
]
}
CV-Generated Annotation Example:
Click to expand annotation JSON
{
"event_start_frame": 40,
"event_start_timestamp": 1635960777652742,
"final_content": {
"ego_behavior_schema": {
"ego_behavior_reasoning": "Ego is decelerating and turning right at the intersection. The lane lines indicate a right turn, and the presence of parked cars on the right suggests the need to navigate carefully. The sun glare may affect visibility, but no other moving vehicles or pedestrians are immediately relevant to the current driving behavior.",
"effect_on_ego_behavior": "Decelerating and turning right, paying attention to parked cars and sun glare.",
"difficulty_score": 3
}
}
}
Reasoning SFT Annotation Example:
Click to expand annotation JSON
{
"response": {
"description": "I'm driving in a residential area. Driving through a four junction road. I check surroundings for any oncoming traffic. I ensure the junction is clear. I proceed to drive straight. I am being very cautious while driving due to rain. Ahead, I am approaching another T junction with stop sign board. I slow down the vehicle and check surroundings for any oncoming traffic. The junction is clear. I proceed to make a left turn. I notice few vehicles are parked on the private drive space. There are many connecting lanes on to the road. I maintain a constant speed and keep a vigilant eye around for any sudden moments.",
"driving difficulty explanation": "I'm driving in rain.",
"notice": [
{
"Between time 10.18s and 17.07s": "Approaching a T junction. I slow down the vehicle and make a left turn."
}
]
}
}
Dataset Summary
| Data Source | Samples |
|---|---|
| Human-Labeled | ~10K |
| CV-Labeled | ~1.1M |
| Reasoning SFT | ~12K |
| Total | ~1.1M |
Video specifications: 5–20 seconds per clip, ~17 MB average size, 1936×1220 resolution.
Since auto-labeled data is abundant, we experiment with sampling ratios to balance quality (human-labeled) and coverage (auto-labeled). The weights parameter in training configuration controls the blend ratio across data sources.
Training Data Preview (10×10 random sample from the training dataset):
4. Post-Training (SFT)
Cosmos-rl provides infrastructure for post-training of Cosmos models. We perform supervised fine-tuning to predict human annotations given video and prompts.
Setup
Follow the example SFT setup instructions in the Cosmos Reason 2 repository. Be sure to install redis-server and log into wandb.
Fine-Tuning Code Structure
The fine-tuning code is located in examples/cosmos_rl/post_training_uber/ and includes:
- System and user prompts (described above)
config/uber_sft_blended.toml: SFT hyperparameters configurationscripts/uber_dataloader.py: Creates a custom dataset combining video clips with prompts and human annotations
Training Configuration
Training Configuration: uber_sft_blended.toml
[custom.dataset]
dataset_root = ... # set as data root
subdirectories = ["cv_annotated", "human_annotated", "reason1_sft"]
# Sampling weights for each subdirectory (must match order of subdirectories)
# These weights control the probability of sampling from each dataset.
# Weights are normalized internally, so [1, 2, 1] is equivalent to [0.25, 0.5, 0.25]
#
# Current setting: 30% cv_annotated, 50% human_annotated, 20% reason1_sft
weights = [0.3, 0.5, 0.2]
meta_file = "meta.json"
[custom.vision]
# NOTE: Use ONLY nframes OR fps, NOT both (framework limitation)
min_pixels = 3136 # 56x56 minimum (4 patches)
max_pixels = 360000 # ~600x600 per frame
nframes = 16 # Fixed number of frames for consistent tokenization
[train]
output_dir = ... # set as output directory
resume = true
compile = false
epoch = 3 # 3 epochs
train_batch_per_replica = 32 # Per-GPU batch size
optm_lr = 2e-7
optm_weight_decay = 0.01
optm_warmup_steps = 0.03
optm_decay_type = "cosine"
optm_grad_norm_clip = 1.0
seed = 42
[policy]
model_name_or_path = "nvidia/Cosmos-Reason2-8B"
model_max_length = 4096
model_gradient_checkpointing = true
[logging]
logger = ['console', 'wandb']
project_name = "cosmos_reason2_av_vqa"
experiment_name = "post_training_uber/av_vqa_sft_blended"
[train.train_policy]
type = "sft"
mini_batch = 4
dataloader_num_workers = 4
[train.ckpt]
enable_checkpoint = true
save_freq = 20
[policy.parallelism]
tp_size = 1
cp_size = 1
dp_shard_size = 8
pp_size = 1
Running Fine-Tuning
To start supervised fine-tuning, navigate to the training directory, activate the virtual environment, and run the cosmos-rl training command with the configuration file:
# In the cosmos-reason2 directory
cd examples/cosmos_rl/post_training_uber
source ../.venv/bin/activate
cosmos-rl --config config/uber_sft_blended.toml scripts/uber_dataloader.py
5. Re-Evaluation
After fine-tuning, we re-evaluate to measure improvements using VQA accuracy.
Running the Fine-Tuned Model
Generate annotations using the fine-tuned model weights:
python run_model_inference.py \
--model-name <model_name> \
--checkpoint <checkpoint_path> \
--dataset <dataset> \
Arguments:
--model-name: Name of the model (e.g., "Cosmos-Reason2-8B")--checkpoint: Path to the fine-tuned checkpoint directory (e.g., "outputs/uber/ckpt-250")--dataset: Dataset name to evaluate on (e.g., "AV_CAPTION")
Scoring the Fine-Tuned Model
Generate visualizations for evaluation metrics:
# Generate metric visualizations
python plot_metric.py \
--dataset <dataset> \
--base-model <base_model_name> \
--metric <metric> \
--outputs-dir <outputs_directory>
Arguments for plot_metric.py:
--dataset: Dataset name (e.g., "AV_CAPTION")--base-model: Base model name for comparison (e.g., "Cosmos-Reason2-8B")--metric: Metric to visualize (e.g., "bleu", "vqa_accuracy", "lingoqa")--outputs-dir: Directory containing inference outputs from different checkpoints
Results
BLEU Scores:
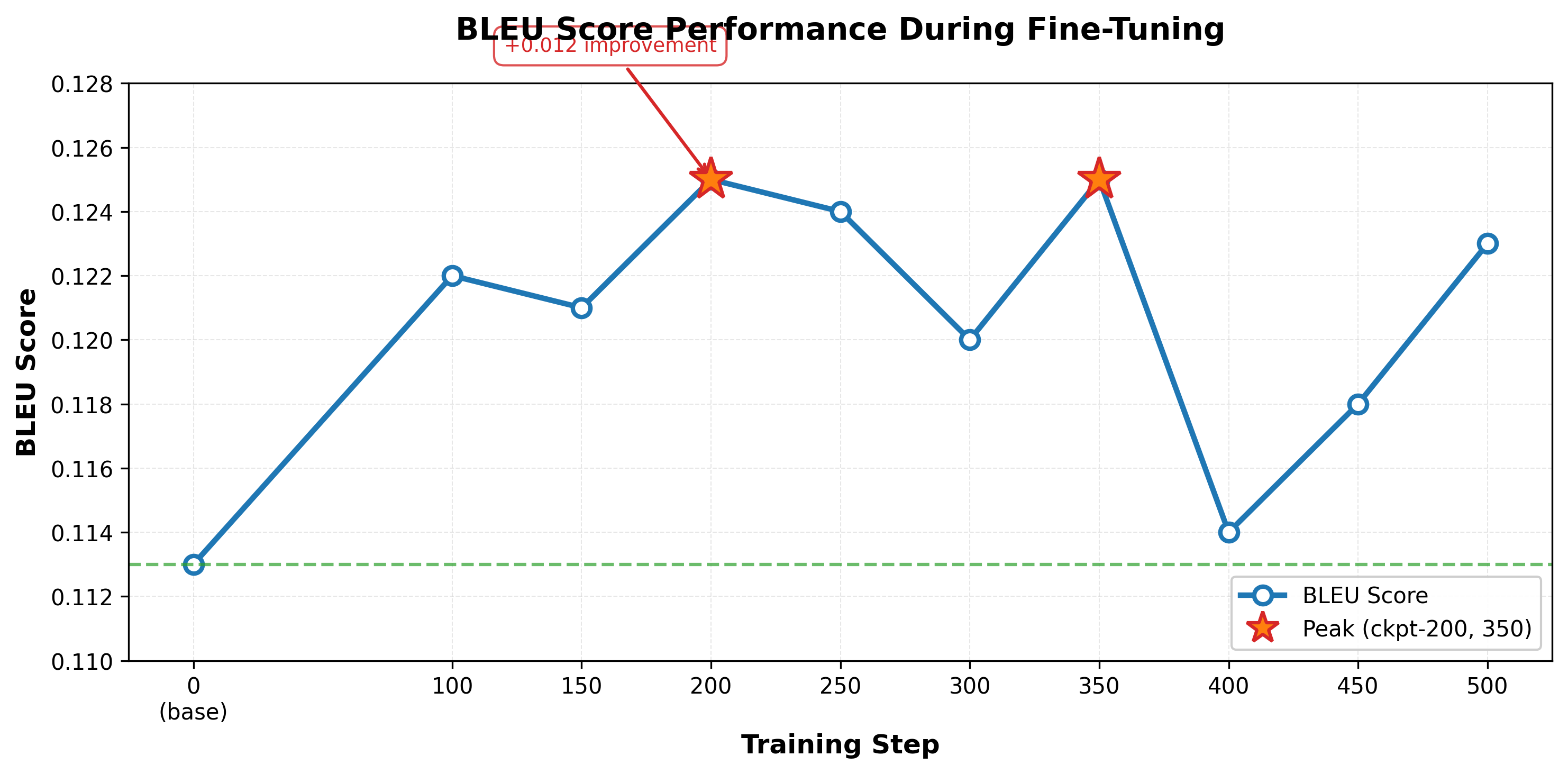
Key Observations:
- Peak Performance: Checkpoints 200 and 350 achieve the highest BLEU score (0.125), representing a 10.6% improvement over the zero-shot baseline (0.113).
- Stability: BLEU scores remain relatively stable across checkpoints (range: 0.113–0.125), with most fine-tuned checkpoints exceeding baseline, suggesting consistent lexical quality throughout training.
- Training Dynamics: Rapid improvement from baseline (0.113) to ckpt-100 (0.122), with peak performance at ckpt-200 and 350. Some fluctuation in later checkpoints, with ckpt-500 (0.123) maintaining near-peak performance.
MCQ-based VQA Results:
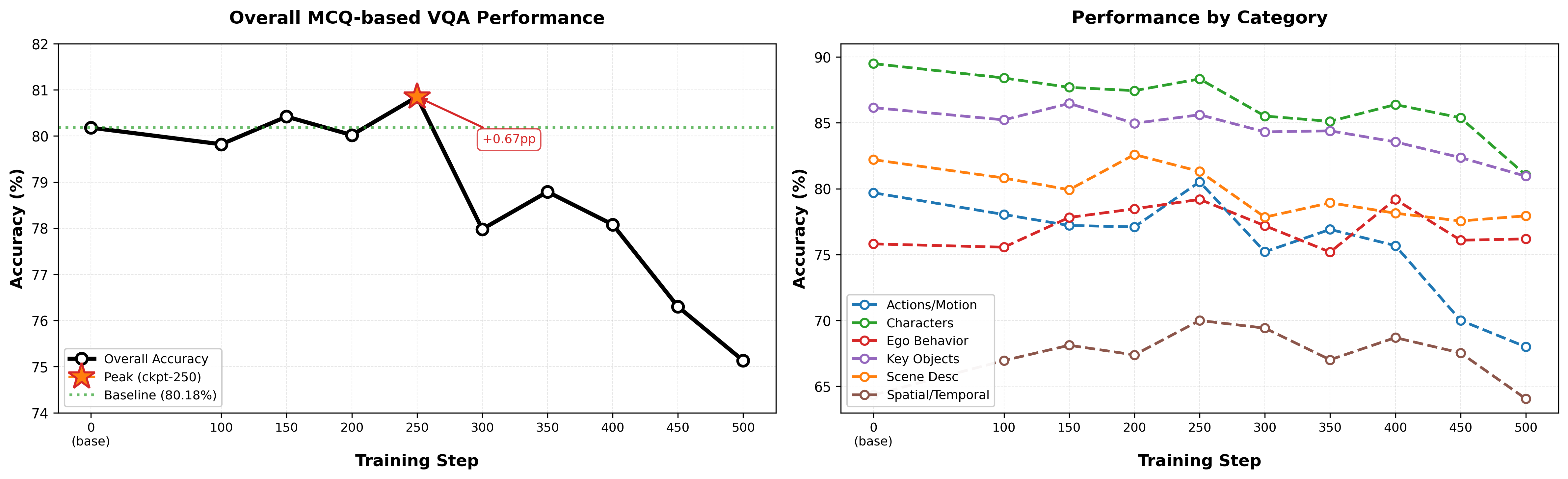
Key Observations:
- Best Checkpoint: ckpt-250 achieves the highest overall accuracy (80.85%), representing a 0.67 percentage point improvement over the zero-shot baseline (80.18% for Cosmos Reason 2-8B).
- Training Trajectory: Performance peaks at ckpt-250, then declines through ckpt-500 (75.13%), with clear signs of overfitting beyond checkpoint 250.
- Category Range: Performance varies from 64–89% across categories, with Spatial & Temporal being the most challenging (baseline: 64.35%, peak: 70.00%) and Characters & Interactions the strongest (baseline: 89.49%, peak: 89.49%).
LingoQA Benchmark Results:
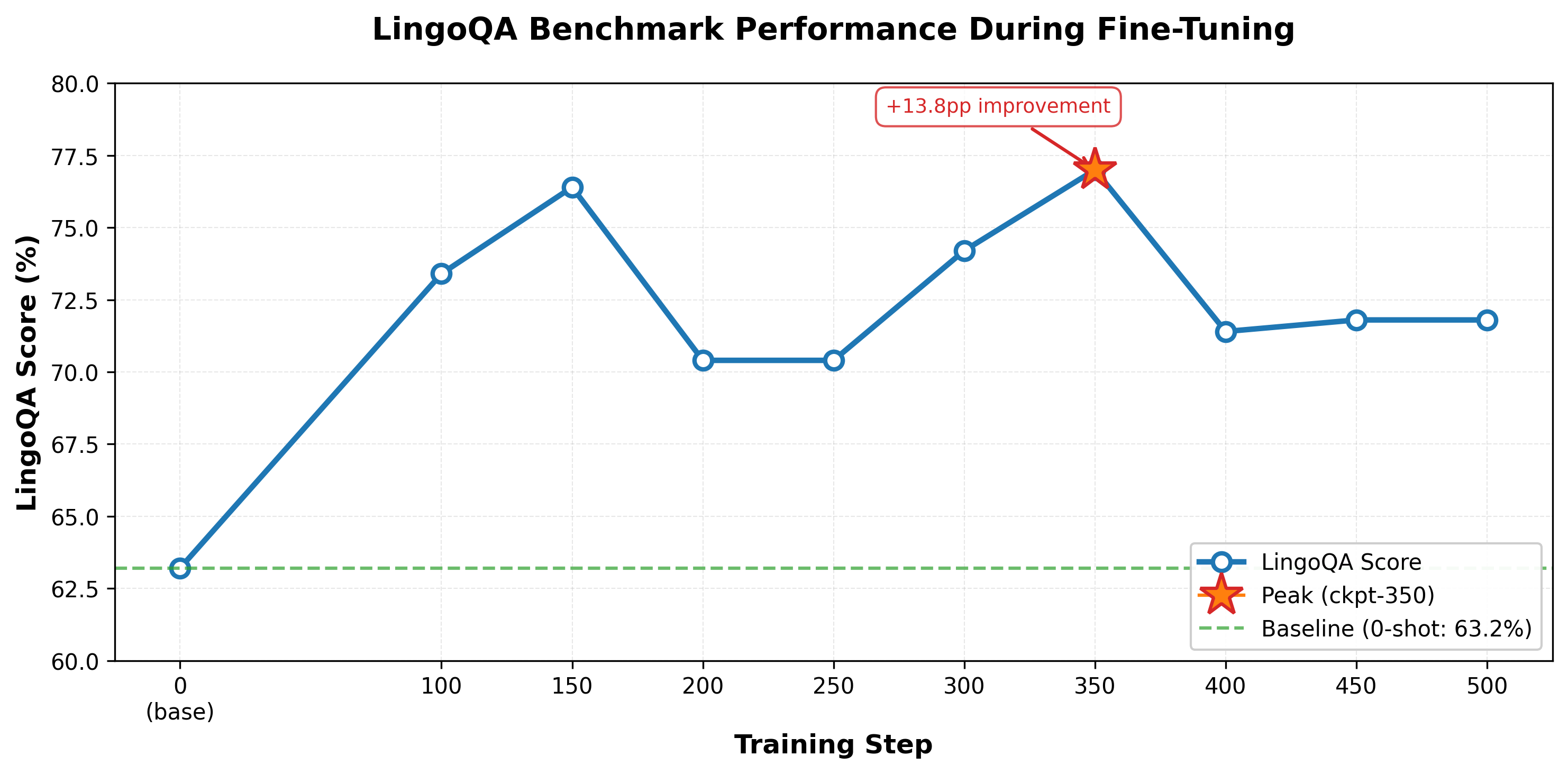
Key Observations:
- Peak Performance: ckpt-350 achieves the highest LingoQA score (77.0%), representing a 13.8 percentage point improvement over the zero-shot baseline (63.2%).
- Training Trajectory: Non-monotonic pattern—rapid improvement from baseline (63.2%) to ckpt-100 (73.4%), further gain to ckpt-150 (76.4%), dip at ckpt-200–250 (70.4%), recovery to peak at ckpt-350 (77.0%), then stabilization around 71–72%.
- Checkpoint Divergence: Unlike MCQ-based VQA where ckpt-250 performs best, LingoQA peaks at ckpt-350, highlighting different optimal checkpoints for internal vs. external benchmarks.
- Generalization: Substantial improvement from 63.2% to 77.0% demonstrates that fine-tuning significantly enhances performance on external benchmarks, validating generalization beyond the training distribution.
Summary:
- Fine-Tuning Success: All three metrics show improvements over zero-shot baselines—BLEU (+10.6%), MCQ-based VQA (+0.67pp), and LingoQA (+13.8pp)—demonstrating effective domain adaptation.
- Optimal Checkpoints:
- ckpt-200 & 350: Best for BLEU score (0.125)
- ckpt-250: Best for internal MCQ-based VQA (80.85% overall accuracy)
- ckpt-350: Best for external LingoQA benchmark (77.0%)
- Category Performance: At peak (ckpt-250), MCQ-based VQA shows: Characters & Interactions (strongest, 88.33%) > Key Objects (85.61%) > Scene Description (81.31%) > Actions & Motion (80.52%) > Ego Behavior (79.19%) > Spatial & Temporal (most challenging, 70.00%).
- Training Dynamics: Performance peaks early (ckpt-200–350 depending on metric), with clear overfitting signals beyond ckpt-300—MCQ VQA drops to 75.13% by ckpt-500, emphasizing the importance of checkpoint selection.
Conclusion
Fine-tuning Cosmos Reason 2-8B on annotated AV videos achieved measurable improvements across all evaluation metrics: BLEU scores improved 10.6% (0.113 → 0.125), MCQ-based VQA gained 0.67 percentage points (80.18% → 80.85%), and LingoQA showed substantial improvement of 13.8 percentage points (63.2% → 77.0%). These gains demonstrate effective domain adaptation for AV applications.
Key findings include: (1) different evaluation metrics peak at different training stages (ckpt-200/350 for BLEU, ckpt-250 for MCQ-based VQA, ckpt-350 for LingoQA), highlighting the importance of multi-benchmark evaluation; (2) clear overfitting signals emerge beyond ckpt-300, with MCQ VQA dropping 5.72 percentage points from peak to ckpt-500, emphasizing the need for careful checkpoint selection; and (3) Spatial & Temporal reasoning, while showing improvement (64.35% → 70.00%), remains the most challenging category, suggesting an area for future work.
The evaluation pipeline combining MCQ-based VQA, BLEU scores, and external benchmarks provides comprehensive assessment that captures both task-specific optimization and generalizable understanding. For production deployment, we recommend ckpt-250 for balanced performance, though checkpoint selection should ultimately balance internal task performance with external generalization based on specific deployment priorities. Continued focus on enhancing Spatial & Temporal reasoning capabilities and exploring regularization techniques to mitigate overfitting will further improve model performance for AV applications.
Future Directions
While the current results demonstrate successful domain adaptation, there remain significant opportunities for further improvement. Post-training is an iterative process requiring meticulous attention to all details—from data quality to hyperparameter selection to evaluation methodology. Although the current results have been refined through multiple tuning iterations across various aspects, several avenues merit further exploration:
-
Hyperparameter Optimization: More comprehensive parameter sweeping could identify optimal learning rates, batch sizes, warmup schedules, and weight decay values that better balance performance and generalization.
-
Data Composition Analysis: Systematic exploration of different dataset mixing ratios (human-annotated, CV-generated, and reasoning SFT data) could reveal more effective blending strategies. The current 30%-50%-20% split was chosen empirically but may not be optimal for all evaluation metrics.
-
Benchmark Refinement: The MCQ-based VQA benchmark was constructed under time and resource constraints. Further validation of ground truth labels, expansion of the question pool, and human verification of edge cases would strengthen the evaluation's reliability and ensure it accurately reflects operational requirements.
-
Training Schedule Optimization: Alternative learning rate schedules, longer training with more aggressive regularization, or curriculum learning strategies could help mitigate overfitting while maintaining peak performance.
These explorations underscore that post-training is fundamentally an iterative refinement process where careful experimentation and validation compound to produce high-quality models.
Related Work
This recipe builds upon our earlier exploratory work: SFT for AV Video Captioning and VQA with Cosmos Reason 1. That recipe demonstrated the viability of fine-tuning vision-language models for AV captioning using public datasets and LLM-as-judge evaluation. This recipe scales the approach with Uber's production data, a more rigorous multi-metric evaluation benchmark, and Cosmos Reason 2's enhanced spatial reasoning capabilities.
References
[1] Marcu, A.-M., Chen, L., Hünermann, J., Karnsund, A., Hanotte, B., Chidananda, P., Nair, S., Badrinarayanan, V., Kendall, A., Shotton, J., Arani, E., & Sinavski, O. (2024). LingoQA: Visual Question Answering for Autonomous Driving. ECCV 2024.
[2] NVIDIA. Cosmos-Reason1: From Physical Common Sense To Embodied Reasoning. arxiv:2503.15558.
[3] NVIDIA. Alpamayo-R1: Bridging Reasoning and Action Prediction for Generalizable Autonomous Driving in the Long Tail. arxiv:2511.00088.
Document Information
Publication Date: January 5, 2026
Citation
If you use this recipe or reference this work, please cite it as:
@misc{cosmos_cookbook_av_captioning_vqa_2026,
title={Post-train Cosmos Reason 2 for Autonomous Vehicle Video Captioning and VQA},
author={Jin, Jingyi and Zhang, Shun and Yang, Xiaodong and Wang, Joseph},
organization={NVIDIA and Uber},
year={2026},
month={January},
howpublished={\url{https://nvidia-cosmos.github.io/cosmos-cookbook/recipes/post_training/reason2/video_caption_vqa/post_training.html}},
note={NVIDIA Cosmos Cookbook}
}
Suggested text citation:
Jingyi Jin, Shun Zhang, Xiaodong Yang, & Joseph Wang (2026). Post-train Cosmos Reason 2 for Autonomous Vehicle Video Captioning and VQA. In NVIDIA Cosmos Cookbook. NVIDIA and Uber. Accessible at https://nvidia-cosmos.github.io/cosmos-cookbook/recipes/post_training/reason2/video_caption_vqa/post_training.html