Physical Plausibility Prediction with Cosmos Reason 2
Authors: Shun Zhang • Zekun Hao • Jingyi Jin Organization: NVIDIA
| Model | Workload | Use Case |
|---|---|---|
| Cosmos Reason 2 | Post-training | Physical plausibility prediction |
Note: For experiments using Cosmos Reason 1, please refer to the Physical Plausibility Prediction with Cosmos Reason 1 recipe.
Overview
In synthetic video generation, it is crucial to determine the quality of the generated videos and filter out videos of bad quality. In this case study, we demonstrate using the Cosmos Reason 2 model for physical plausibility prediction. Physics plausibility assessment involves evaluating whether the physical interactions and behaviors observed in videos are consistent with real-world physics laws and constraints.
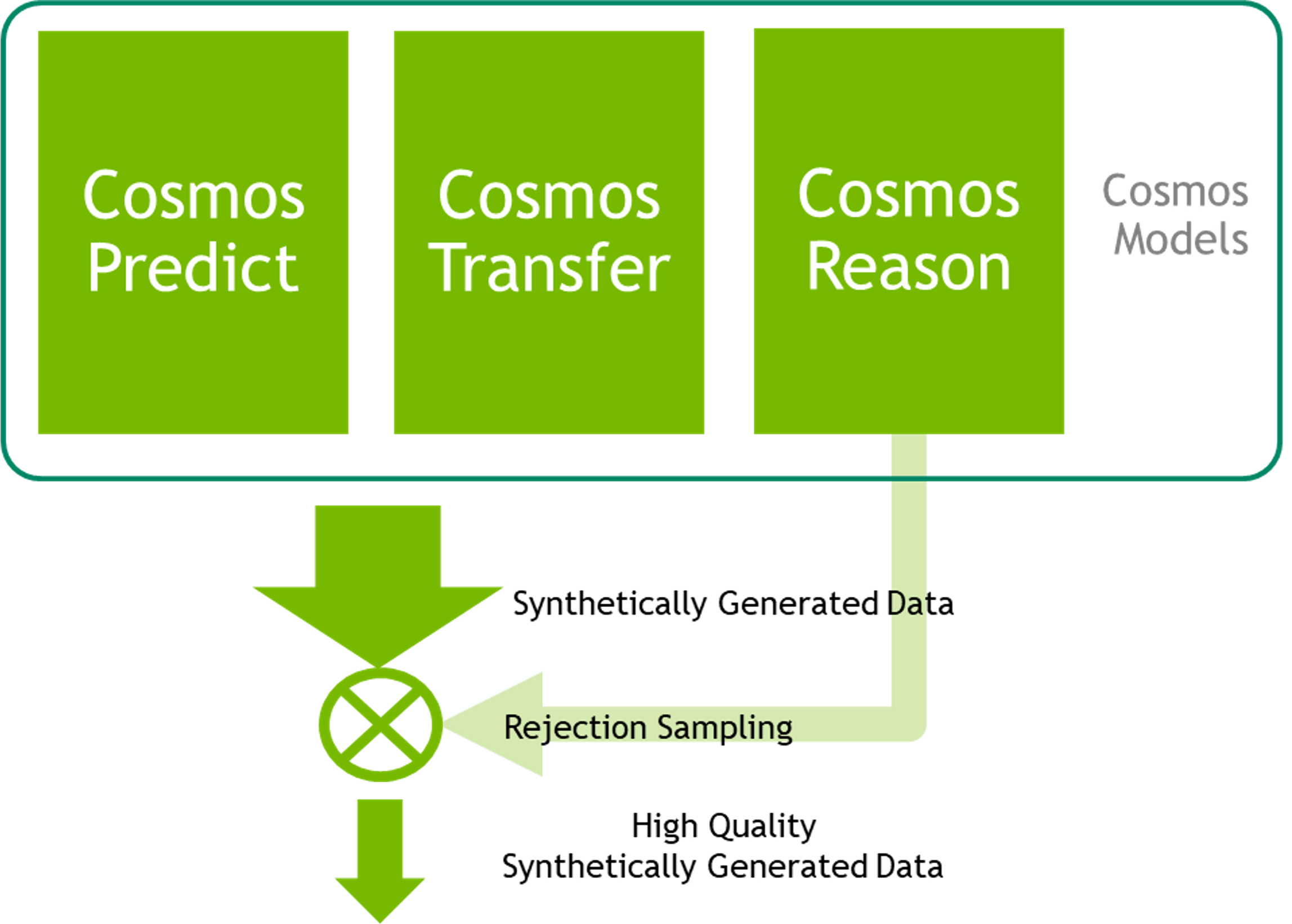
When generating synthetic videos using generative models (e.g., Cosmos Predict or Cosmos Transfer), we filter out videos that are not physically plausible before including them in downstream datasets or tasks (illustrated in the figure above).
We first evaluate the model's ability to predict physical plausibility on an open-source dataset. We then fine-tune the model and evaluate its performance.
Dataset: VideoPhy-2
We use the VideoPhy-2 dataset for this case study, which is designed as an action-centric benchmark for evaluating physical common sense in generated videos.
Dataset Overview
VideoPhy-2 provides a comprehensive evaluation framework for testing how well models understand and predict physical plausibility in video content. The dataset features human evaluations on physics adherence using a standardized 1-5 point scale.
| Dataset Split | Size | Access |
|---|---|---|
| Training Set | 3.4k videos | videophysics/videophy2_train |
| Evaluation Set | 3.3k videos | videophysics/videophy2_test |
Evaluation Criteria
Each video receives human evaluations based on adherence to physical laws using a standardized 5-point scale:
| Score | Description | Physics Adherence |
|---|---|---|
| 1 | No adherence to physical laws | Completely implausible |
| 2 | Poor adherence to physical laws | Mostly unrealistic |
| 3 | Moderate adherence to physical laws | Mixed realistic/unrealistic |
| 4 | Good adherence to physical laws | Mostly realistic |
| 5 | Perfect adherence to physical laws | Completely plausible |
Key Physics Challenges
The dataset highlights critical challenges for generative models in understanding fundamental physical rules:
- Conservation Laws: Mass, energy, and momentum conservation
- Gravitational Effects: Realistic falling and weight behavior
- Collision Dynamics: Object interaction physics
- Temporal Causality: Cause-and-effect relationships
- Spatial Constraints: Object boundaries and spatial logic
Example Videos from the Dataset
Low Physical Plausibility (Score: 2/5)
-
Scene: A robotic arm gently pokes a stack of plastic cups.
-
Physics Issue: The stack of cups does not maintain its shape when the robotic arm interacts with it.
-
Key Problems: Conservation of mass and elasticity.
High Physical Plausibility (Score: 4/5)
-
Scene: A robotic arm pushes a metal cube off a steel table.
-
Physics Strengths: The robotic arm moves the cube from one position to another. The cube maintains its shape and volume throughout the interaction.
-
Key Success: Conservation of mass and gravity.
Zero-Shot Inference
We first evaluate the model's ability to predict physical plausibility on the VideoPhy-2 evaluation set without any fine-tuning. We modified the prompt from the VideoPhy-2 paper to fit the Cosmos Reason 2 prompt format.
Prompt for Scoring Physical Plausibility
system_prompt: "You are a helpful assistant."
user_prompt: |
You are a helpful video analyzer. Evaluate whether the video follows physical commonsense.
Evaluation Criteria:
1. **Object Behavior:** Do objects behave according to their expected physical properties (e.g., rigid objects do not deform unnaturally, fluids flow naturally)?
2. **Motion and Forces:** Are motions and forces depicted in the video consistent with real-world physics (e.g., gravity, inertia, conservation of momentum)?
3. **Interactions:** Do objects interact with each other and their environment in a plausible manner (e.g., no unnatural penetration, appropriate reactions on impact)?
4. **Consistency Over Time:** Does the video maintain consistency across frames without abrupt, unexplainable changes in object behavior or motion?
Instructions for Scoring:
- **1:** No adherence to physical commonsense. The video contains numerous violations of fundamental physical laws.
- **2:** Poor adherence. Some elements follow physics, but major violations are present.
- **3:** Moderate adherence. The video follows physics for the most part but contains noticeable inconsistencies.
- **4:** Good adherence. Most elements in the video follow physical laws, with only minor issues.
- **5:** Perfect adherence. The video demonstrates a strong understanding of physical commonsense with no violations.
Response Template:
Analyze the video carefully and answer the question according to the following template:
[Score between 1 and 5.]
Example Response:
2
Does this video adhere to the physical laws?
Note: Since Cosmos Reason 2 is fine-tuned from Qwen3-VL, we follow their prompt guidelines: The system prompt should be set to "You are a helpful assistant", and the model response does not have a <answer> tag (see the Qwen3-VL GitHub repository for more details).
Evaluation Metrics
We evaluate the model performance using two key metrics:
- Accuracy: The percentage of videos where predicted scores match ground truth scores (exact integer match)
- Correlation: The Pearson correlation between predicted and ground truth scores
Setup
To run zero-shot inference, you need to clone both repositories and copy the necessary files:
- Clone the Cosmos Reason 2 repository:
- Clone the cosmos-cookbook repository (this repository):
- Copy the
video_criticfolder from the cosmos-cookbook repository to your Cosmos Reason 2 clone:
# Adjust paths based on where you cloned the repositories
cp -r cosmos-cookbook/scripts/examples/reason2/physical-plausibility-check/video_critic cosmos-reason2/examples/
- Copy the prompt file from the cosmos-cookbook repository to your Cosmos Reason 2 repository (shown in the "Prompt for Scoring Physical Plausibility" section above):
# Adjust paths based on where you cloned the repositories
cp cosmos-cookbook/docs/recipes/post_training/reason2/physical-plausibility-check/assets/video_reward.yaml cosmos-reason2/prompts/video_reward.yaml
Running Zero-Shot Inference
Run inference on the VideoPhy-2 test set using Cosmos Reason 2. From the Cosmos Reason 2 project root directory:
uv run examples/video_critic/inference_videophy2.py \
--model nvidia/Cosmos-Reason2-8B \
--output-dir results/videophy2_test \
--dataset videophysics/videophy2_test \
--split test \
--input-file prompts/video_reward.yaml
Arguments:
--model: Model name or path--output-dir: Output directory for JSON results--dataset: HuggingFace dataset name--split: Dataset split (the dataset only has a "test" split)--input-file: Path to prompt YAML file--revision: Optional model revision/branch
Output:
- Each video gets a JSON file containing:
video_url: Source video URLground_truth: Ground truth physics scoreoutput_text: Model output textpred_score: Parsed predicted score
Computing Evaluation Metrics
After running inference, compute accuracy and correlation metrics from the inference results. From the Cosmos Reason 2 project root directory:
Output:
- Prints accuracy (exact integer match percentage), Pearson correlation, and number of samples
- Generates
summary.jsonin the output directory withaccuracy,pearson_correlation, andnum_samplesmetrics
Results
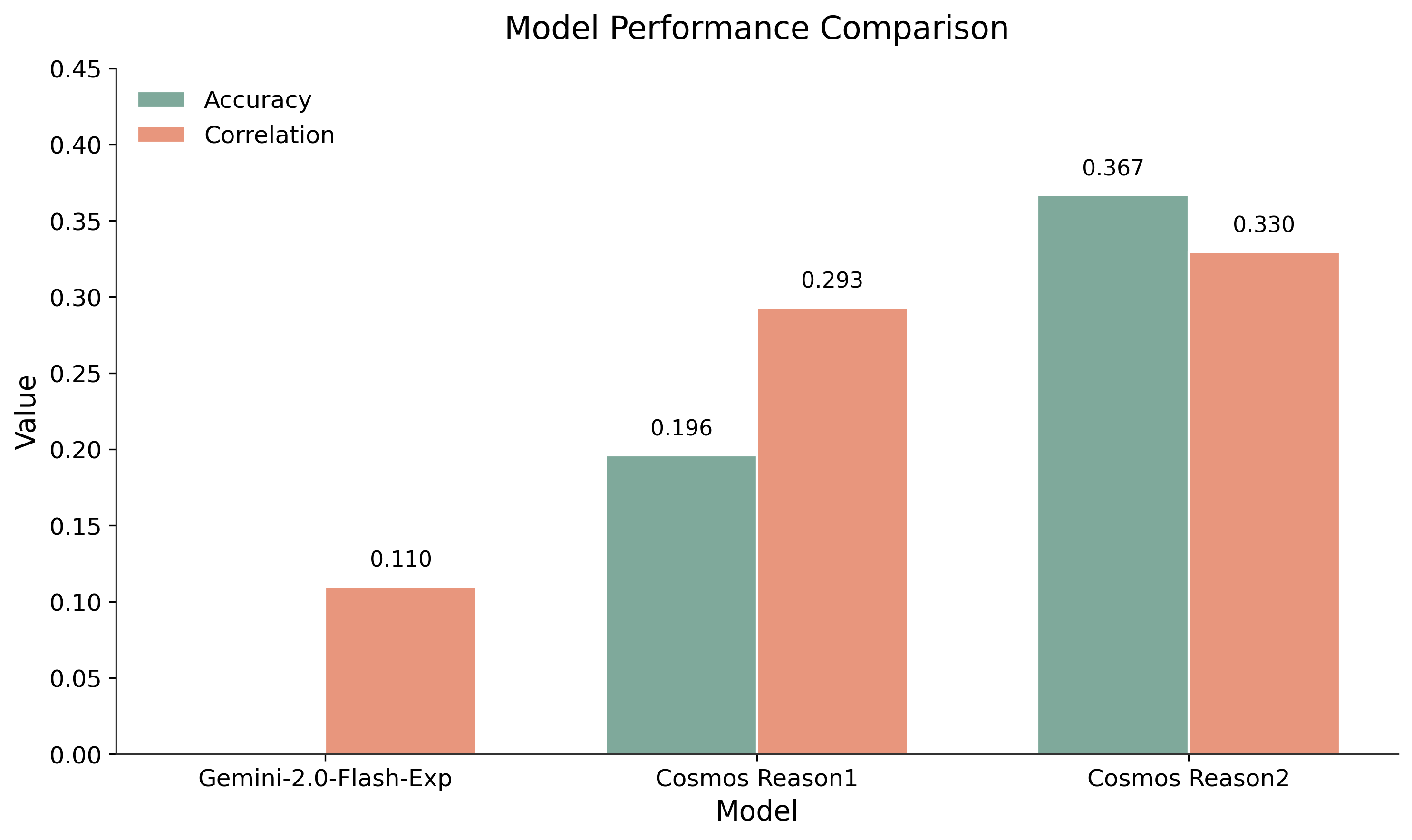
We compare Cosmos Reason 2 with Gemini-2.0-Flash-Exp (the baseline from the paper) and Cosmos Reason 1. Even without fine-tuning, Cosmos Reason 2 demonstrates better performance than both baselines on both accuracy and correlation metrics.
Supervised Fine-Tuning (SFT)
Having demonstrated that Cosmos Reason 2 can predict physical plausibility, we now apply supervised fine-tuning (SFT) using the VideoPhy-2 training set to further improve the model's performance.
Training Data Format
The fine-tuning process uses the following data structure:
- Input: Video + language instruction (from the evaluation prompt)
- Output: Physical plausibility score (1-5 scale)
Data Pre-processing
Before fine-tuning, prepare the VideoPhy-2 training dataset. From the Cosmos Reason 2 project root directory:
uv run examples/video_critic/download_videophy2_train.py \
--dataset videophysics/videophy2_train \
--split train \
--output data/videophy2_train \
--prompt_path prompts/video_reward.yaml
Arguments:
--output: Output directory for the prepared dataset (required)--dataset: HuggingFace dataset name--split: Dataset split to download (the dataset only has a "train" split)--prompt_path: Path to prompt YAML file
The script will:
- Automatically download videos from URLs in the HuggingFace dataset (no manual download needed)
- Create conversations using the prompt template
- Save the dataset in HuggingFace format for training
Training Configuration
We use the following configuration optimized for 8 GPUs:
Training Configuration
[custom.dataset]
path = "../../data/videophy2_train"
[train]
seed = 42
train_batch_per_replica = 32
epoch = 10
optm_lr = 1e-6
optm_weight_decay = 0.01
optm_warmup_steps = 0.03
optm_decay_type = "cosine"
optm_grad_norm_clip = 1.0
output_dir = "../../outputs/videophy2_sft_cosmos_rl"
compile = false
[policy]
model_name_or_path = "nvidia/Cosmos-Reason2-8B"
model_max_length = 4096
[logging]
logger = ['console', 'wandb']
project_name = "cosmos_reason2_physical_plausibility"
experiment_name = "cosmos_rl/videophy2_sft"
[train.train_policy]
type = "sft"
conversation_column_name = "conversations"
mini_batch = 4
[train.ckpt]
enable_checkpoint = true
max_keep = 20
[policy.parallelism]
tp_size = 1
cp_size = 1
dp_shard_size = 8
pp_size = 1
Note: The configuration file is included in the
video_criticfolder that you copied from cosmos-cookbook. Setdp_shard_sizeto the number of GPUs you are using. We tested on A100/H100 GPUs where the model fits in the memory of a GPU, so we only use data parallelism. If you use GPUs with less memory, you may increasetp_sizeto enable tensor parallelism.
We performed hyperparameter search across different learning rates (1e-5, 2e-7, and 1e-6) and found that 1e-6 performs best overall, which is used in the configuration file above.
Running Training
To fine-tune the model on the prepared dataset, first activate the conda environment where you installed redis (as part of the setup guide). Then from the Cosmos Reason 2 project root directory:
cd examples/cosmos_rl
uv run cosmos-rl --config ../video_critic/configs/videophy2_sft.toml scripts/hf_sft.py
Output:
- Checkpoints saved to
outputs/videophy2_sft/{timestamp}/safetensors/step_* - Training logs in WandB (if configured)
Evaluating Fine-tuned Checkpoints
After fine-tuning, evaluate checkpoints by running inference and then computing metrics:
- Run inference on the test set using a checkpoint. Replace
{timestamp}and{number}with the actual timestamp and step number of the checkpoint.
uv run examples/video_critic/inference_videophy2.py \
--model outputs/videophy2_sft/{timestamp}/safetensors/step_{number} \
--output-dir results/videophy2_test_sft_step_{number} \
--dataset videophysics/videophy2_test \
--split test \
--input-file prompts/video_reward.yaml
- Compute metrics for the checkpoint. From the Cosmos Reason 2 project root directory:
This will generate a summary.json file with accuracy, correlation, and sample count metrics, allowing you to compare different checkpoints and select the best one.
Results
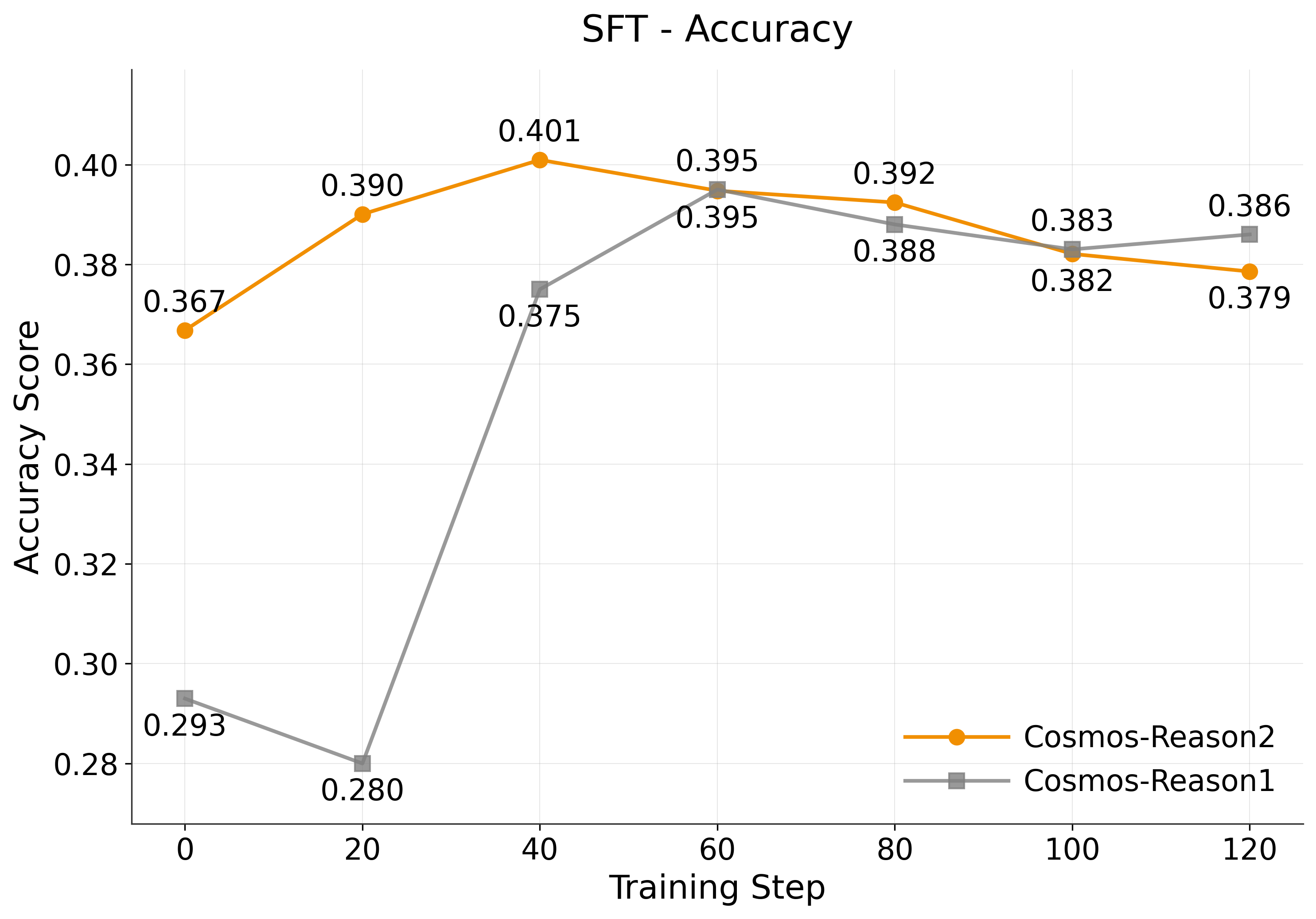
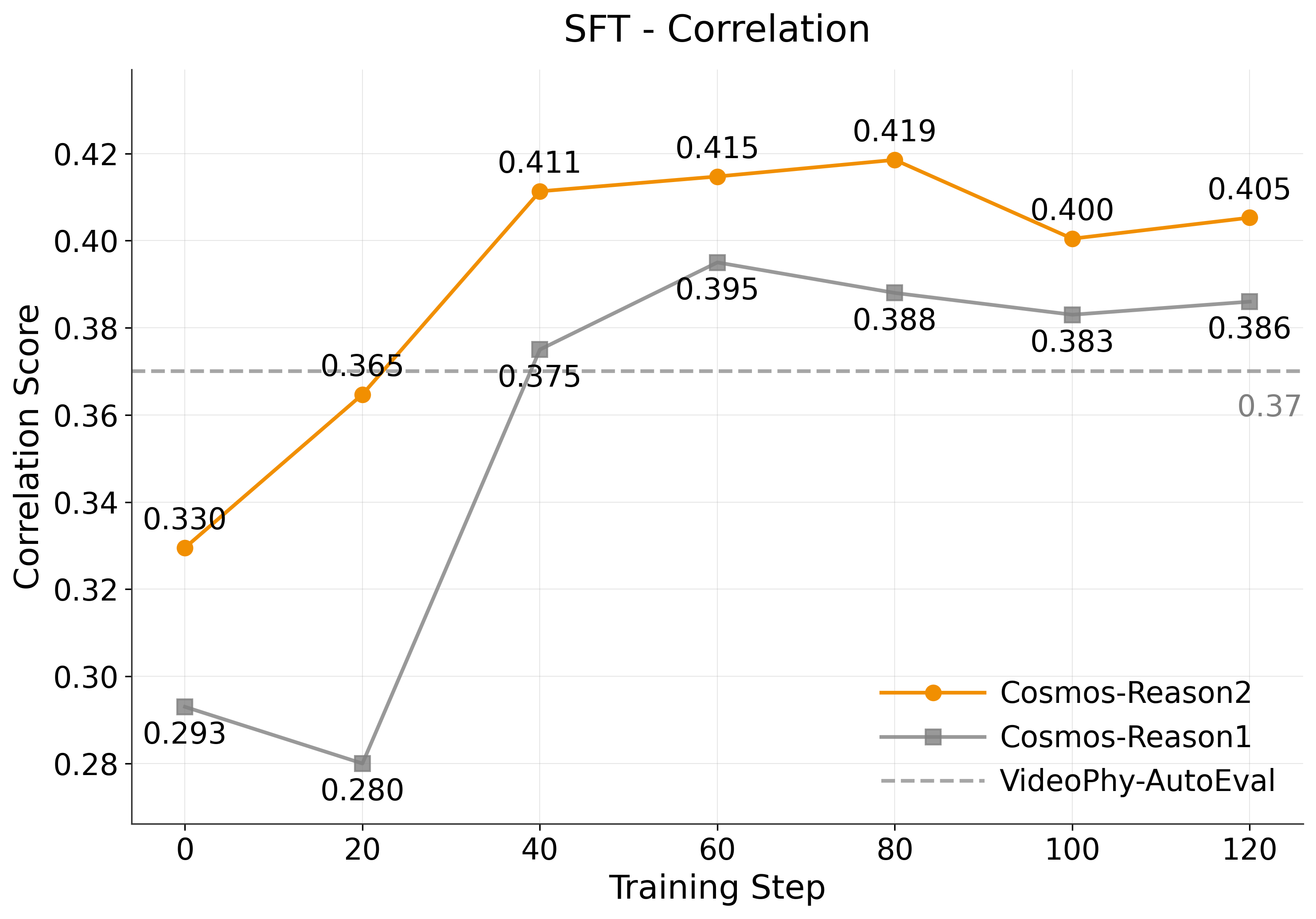
After fine-tuning, we evaluate the model on the VideoPhy-2 evaluation set using the same metrics. The results demonstrate significant performance improvements. VideoPhy-AutoEval is the baseline model from the VideoPhy-2 paper.
Observations:
-
Accuracy Trajectory: Cosmos Reason 2 achieves its best accuracy of 0.401 at step 40, outperforming Cosmos Reason 1's peak of 0.395 at step 60. However, the accuracy of both Reason 1 and Reason 2 declines after step 40, showing signs of overfitting.
-
Correlation Performance: Cosmos Reason 2 consistently outperforms Cosmos Reason 1 in correlation at all training steps, achieving its best correlation of 0.419 at step 80, compared to Reason 1's peak of 0.395 at step 60. Additionally, Reason 2 reaches a correlation score similar to VideoPhy-AutoEval at step 20, which requires a smaller number of training steps compared to Reason 1.
-
Improvement Trend: The improvement trend is more consistent across both metrics compared to Reason 1.
Example: Model Prediction Before and After Fine-tuning
- Model prediction (before fine-tuning): 3
- Model prediction (after fine-tuning): 2
- Ground truth: 2 (poor adherence to physical laws)
- Model prediction (before fine-tuning): 3
- Model prediction (after fine-tuning): 2
- Ground truth: 1 (no adherence to physical laws; completely implausible)
After fine-tuning, Cosmos Reason 2 correctly identifies the low physical plausibility of the videos, matching human judgment. In contrast, the base model, prior to fine-tuning, overestimated plausibility.
Conclusion
Supervised fine-tuning on the VideoPhy-2 dataset significantly improves physical plausibility prediction for Cosmos Reason 2, progressing from zero-shot to best SFT performance. Key insights:
-
Strong Baseline: Cosmos Reason 2 demonstrates better zero-shot performance compared to Cosmos Reason 1, achieving 25% higher accuracy and 12% higher correlation before any fine-tuning, indicating improved physics reasoning capabilities in the base model.
-
Metric-Specific Optimization: Different metrics peak at different training steps (accuracy at step 40, correlation at step 80), suggesting that practitioners should select checkpoints based on their primary evaluation metric or use ensemble approaches.
-
Consistent Improvements: Fine-tuning delivers measurable gains in both metrics, with correlation showing more sustained improvement (reaching 0.419) compared to accuracy, which peaks earlier and then stabilizes.
-
Flexibility: This methodology can be adapted to other video quality assessment tasks by substituting the datasets and defining appropriate metrics. The better zero-shot performance of Cosmos Reason 2 also suggests it may require less fine-tuning data to achieve target performance levels.
Document Information
Publication Date: January 27, 2026
Citation
If you use this recipe or reference this work, please cite it as:
@misc{cosmos_cookbook_physical_plausibility_prediction_2026,
title={Physical Plausibility Prediction with Cosmos Reason 2},
author={Zhang, Shun and Hao, Zekun and Jin, Jingyi},
year={2026},
month={January},
howpublished={\url{https://nvidia-cosmos.github.io/cosmos-cookbook/recipes/post_training/reason2/physical-plausibility-check/post_training.html}},
note={NVIDIA Cosmos Cookbook}
}
Suggested text citation:
Shun Zhang, Zekun Hao, & Jingyi Jin (2026). Physical Plausibility Prediction with Cosmos Reason 2. In NVIDIA Cosmos Cookbook. Accessible at https://nvidia-cosmos.github.io/cosmos-cookbook/recipes/post_training/reason2/physical-plausibility-check/post_training.html