Cosmos Policy: Fine-Tuning Video Models for Visuomotor Control and Planning
Authors: Moo Jin Kim • Yuzhu Dong • Jinwei Gu
Organizations: NVIDIA, Stanford University
Cosmos Policy website: https://research.nvidia.com/labs/dir/cosmos-policy/
Overview
| Model | Workload | Use Case |
|---|---|---|
| Cosmos-Predict2-2B-Video2World | Post-training | Vision-based robotic manipulation and model-based planning |
| Cosmos-Predict2.5-2B-Video2World | Post-training | Vision-based robotic manipulation and model-based planning |
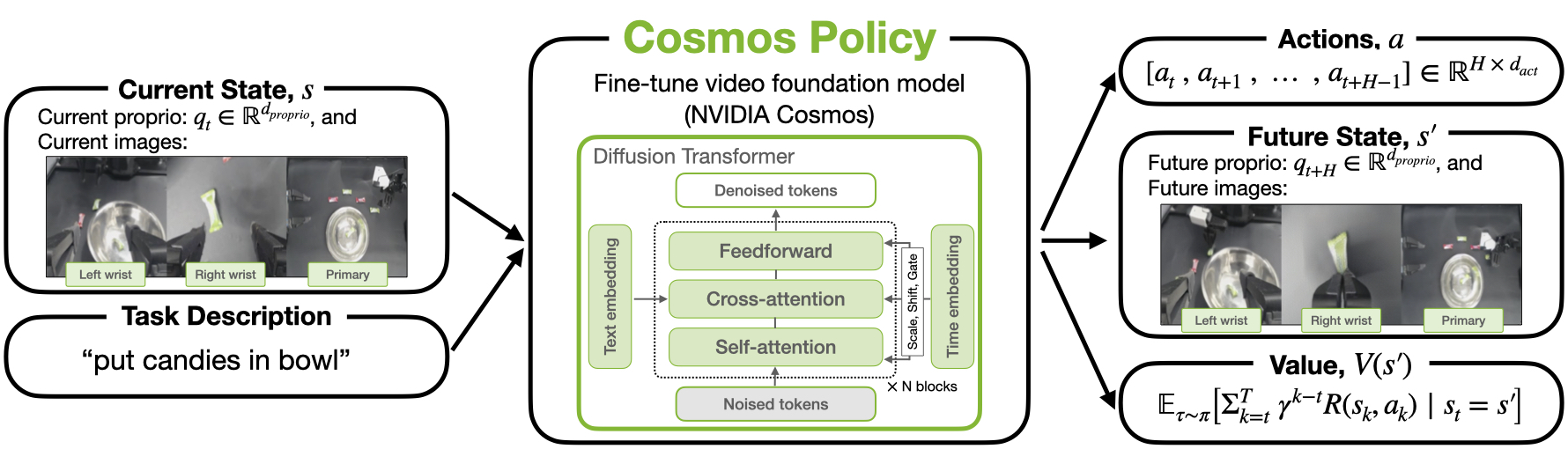
Cosmos Policy adapts the Cosmos-Predict2-2B and Cosmos-Predict2.5-2B-Video2World video foundation model into a state-of-the-art robot policy through a single stage of post-training on robot demonstration data, with no architectural modifications. The approach leverages the video model's pretrained priors to:
- Generate robot actions
- Predict future states (robot proprioception and camera images)
- Estimate values (expected cumulative rewards)
Below we show sample rollouts with Cosmos Policy in RoboCasa simulation tasks (top row), as well as its future image predictions (bottom row).
This recipe demonstrates how to fine-tune Cosmos-Predict for robotic manipulation tasks using "latent frame injection": directly encoding new modalities (actions, robot proprioceptive state, and future state value) into the video model's latent diffusion sequence. We discuss three examples: the LIBERO simulation benchmark tasks, the RoboCasa simulation benchmark tasks, and real-world ALOHA robot tasks.
Why does the policy need to predict future state and values? This is because Cosmos Policy was originally designed so that the user can deploy it in one of two ways:
- as a direct policy (where you just immediately execute the action chunk that the model generates, without any sophisticated planning)
- with model-based planning (where you generate multiple action chunk proposals, future states, and values, and select the action chunk with the highest value).
It turns out that even deploying Cosmos Policy as a direct policy without any planning leads to state-of-the-art results, while model-based planning can lead to additional gains in performance at the cost of more complexity and slower inference speed. Therefore, for simplicity, this cookbook recipe focuses on the former: training a vanilla Cosmos Policy and deploying it as a direct policy. (You can refer to the Cosmos Policy paper for more details on the latter.)
The Challenge: Adapting Video Models for Robot Control
Large pretrained video models learn temporal causality, implicit physics, and motion patterns from millions of videos. However, prior approaches to adapting video models for robotics require:
- Multiple training stages (e.g., video fine-tuning on robot data followed by action module training)
- New architectural components (e.g., separate action diffusers or inverse dynamics models)
- Custom model designs that cannot leverage pretrained video priors (e.g., Unified Video Action model and Unified World Model)
In contrast, Cosmos Policy takes a simpler approach:
- One stage of training directly on robot demonstrations
- No architectural changes to the base video model
- Joint policy, world model, and value function in one unified architecture
Method: Latent Frame Injection
Core Concept
Cosmos Policy encodes new input/output modalities directly as latent frames within the video model's latent diffusion sequence. Given the video model's \((1 + T') \times H' \times W' \times 16\) latent sequence, we interleave:
- Robot proprioception (robot joint angles or end-effector pose)
- Action chunks (sequences of actions spanning multiple timesteps)
- Future state values (expected cumulative rewards)
- Multi-camera viewpoint images (e.g., from third-person, wrist-mounted cameras)
The latent sequence follows the structure \((s, a, s', V(s'))\). Below is an example of the latent sequence for RoboCasa simulation tasks. The green "conditioning subsequence" frames are what condition the model's generations; the red "target subsequence" frames are what the model is trained to denoise/generate via reverse diffusion.
| Position | Content | Description |
|---|---|---|
| 0 | (Not depicted above) Blank/Null | Placeholder latent frame (for compatibility with the video model's \((1 + T')\) temporal compression) |
| 1 | Current proprio | Robot proprioceptive state |
| 2-4 | Current images | 1 wrist + 2 third-person cameras |
| 5 | Action chunk | Predicted \(K \times d_{act}\) actions |
| 6 | Future proprio | Predicted robot proprioceptive state (part of the "future state") |
| 7-9 | Future images | Predicted camera views (part of the "future state") |
| 10 | Value | Expected rewards-to-go from the predicted future state |
For LIBERO and ALOHA, the latent diffusion sequence differs slightly. For example, in LIBERO, there are only two camera images (from one third-person camera and one wrist-mounted camera), so there are two fewer total latent frames. For ALOHA, there are three camera images, but from one third-person camera and two wrist-mounted cameras.
Preprocessing Non-Image Modalities for Latent Injection
For robot proprioception, actions, and values, we preprocess these as follows before training the Cosmos Policy:
- Normalize each modality to \([-1, +1]\)
- Flatten into a vector (e.g., action chunk: \(K \times d_{act}\))
- Duplicate the vector as many times necessary to fill the corresponding latent volume \((H' \times W' \times C')\)
- Inject by overwriting placeholder latent frames
At inference time, we extract the predictions from the latent volumes, and since there are duplicates, we simply average across all duplicates and un-normalize to the original modality's scale.
Training Methodology
Joint Training Objectives
Cosmos Policy jointly learns a policy, world model, and value function in one unified model using a balanced batch splitting scheme:
| Objective | Batch % | Learns |
|---|---|---|
| Policy | 50% | \(p(a, s', V(s') \mid s)\) |
| World Model | 25% | \(p(s', V(s') \mid s, a)\) |
| Value Function | 25% | \(p(V(s') \mid s, a, s')\) |
The conditioning scheme determines which latent frames are clean (conditioning) vs. noised (target):
Policy Training: [s] → [a, s', V(s')]
World Model Training: [s, a] → [s', V(s')]
Value Training: [s, a, s'] → [V(s')]
Training Configuration
Key hyperparameters:
| Parameter | LIBERO (Predict2) | LIBERO (Predict2.5) | RoboCasa (Predict2) | RoboCasa (Predict2.5) | ALOHA (Predict2) |
|---|---|---|---|---|---|
| Batch size (global) | 1920 | 1920 | 800 | 800 | 200 |
| Gradient steps | 40K | 40K | 45K | 45K | 50K |
| Action chunk size | 16 | 16 | 32 | 32 | 50 |
| Learning rate | 1e-4 | 2e-4 | 1e-4 | 2e-4 | 1e-4 |
| LR decay step | 30K | 42k | 30K | 42k | 20K |
Noise Distribution Modifications
Cosmos policy (predict2) uses a hybrid log-normal-uniform noise distribution during training, for improved action prediction at test time:
- 70% of samples: Sample from the base video model's original log-normal distribution
- 30% of samples: Sample from a uniform distribution over \([1.0, 85.0]\)
At inference, set \(\sigma_{max} = 80\) and \(\sigma_{min} = 4\) (instead of 0.002), which we empirically found leads to more accurate predictions.
For Cosmos policy (predict2.5), a timestep t is drawn logit-normal distribution with a shift of 5. We observed improved test-time performance with higher shift values, as this biases training toward the high-noise regime. However, setting the shift too high can also degrade performance.
Setup and System Requirements for Inference and Training
Hardware Requirements
Inference (base version without model-based planning):
| Environment | GPU Memory |
|---|---|
| LIBERO simulation | 6.8 GB |
| RoboCasa simulation | 8.9 GB |
| Real-world ALOHA robot | 6.0 GB |
Inference (advanced version with model-based planning):
- Minimum (serial): 1 GPU with 10.0 GB VRAM
- Recommended (parallel): N GPUs with 10.0 GB VRAM each for best-of-N search
Training:
| Dataset | GPUs | Training Time |
|---|---|---|
| ALOHA (~185 demos) | 8 H100s (80GB) | 48 hours |
| RoboCasa (~1200 demos) | 32 H100s (80GB) | 48 hours |
| LIBERO (~2000 demos) | 64 H100s (80GB) | 48 hours |
Software Setup
Note: for Cosmos policy (predict 2), the code lives in Cosmos Policy GitHub repo, for Cosmos policy (predict2.5), the code live in the Cosmos Predict2.5 Github repo Clone the repo from above based on the version, build the Docker container, and launch an interactive session:
Cosmos policy (predict 2):
Cosmos policy (predict2.5):
git clone git@github.com:nvidia-cosmos/cosmos-predict2.5.git
cd cosmos_predict2/_src/predict2/cosmos_policy
docker build -t cosmos-policy docker
docker run \
-u root \
-e HOST_USER_ID=$(id -u) \
-e HOST_GROUP_ID=$(id -g) \
-v $HOME/.cache:/home/cosmos/.cache \
-v $(pwd):/workspace \
--gpus all \
--ipc=host \
-it \
--rm \
-w /workspace \
--entrypoint bash \
cosmos-policy
Build and run docker:
# Build the Docker image
docker build -t cosmos-policy docker
# Launch interactive session
docker run \
-u root \
-e HOST_USER_ID=$(id -u) \
-e HOST_GROUP_ID=$(id -g) \
-v $HOME/.cache:/home/cosmos/.cache \
-v $(pwd):/workspace \
--gpus all \
--ipc=host \
-it \
--rm \
-w /workspace \
--entrypoint bash \
cosmos-policy
Install dependencies for your target environment:
# For LIBERO
uv sync --extra cu128 --group libero --python 3.10
# For RoboCasa
uv sync --extra cu128 --group robocasa --python 3.10
# For ALOHA
uv sync --extra cu128 --group aloha --python 3.10
Data Preparation
Here we discuss how to prepare the datasets for Cosmos Policy training. Skip ahead to the Inference section below if you simply wish to run inference / evaluate with the pretrained Cosmos Policy checkpoints available on Hugging Face.
Downloading Preprocessed Datasets
Preprocessed datasets that are ready for Cosmos Policy training are provided on Hugging Face:
- https://huggingface.co/datasets/nvidia/LIBERO-Cosmos-Policy
- https://huggingface.co/datasets/nvidia/RoboCasa-Cosmos-Policy
- https://huggingface.co/datasets/nvidia/ALOHA-Cosmos-Policy
You can download these datasets and inspect what training data for Cosmos Policy should look like.
To download, run the commands below in a directory that you will use as the base datasets directory (same for both Cosmos policy (predict2) and Cosmos policy (predict2.5)):
LIBERO:
hf download nvidia/LIBERO-Cosmos-Policy --repo-type dataset --local-dir LIBERO-Cosmos-Policy
export BASE_DATASETS_DIR=$(pwd)
RoboCasa:
hf download nvidia/RoboCasa-Cosmos-Policy --repo-type dataset --local-dir RoboCasa-Cosmos-Policy
export BASE_DATASETS_DIR=$(pwd)
git clone https://github.com/moojink/robocasa-cosmos-policy.git
uv pip install -e robocasa-cosmos-policy
uv run --extra cu128 --group robocasa --python 3.10 robocasa-cosmos-policy/robocasa/scripts/download_kitchen_assets.py
uv run --extra cu128 --group robocasa --python 3.10 robocasa-cosmos-policy/robocasa/scripts/setup_macros.py
# Downloads to a local directory called `RoboCasa-Cosmos-Policy`
hf download nvidia/RoboCasa-Cosmos-Policy --repo-type dataset --local-dir RoboCasa-Cosmos-Policy
# Set the current base datasets directory as BASE_DATASETS_DIR (needed for training)
ALOHA:
hf download nvidia/ALOHA-Cosmos-Policy --repo-type dataset --local-dir ALOHA-Cosmos-Policy
export BASE_DATASETS_DIR=$(pwd)
Training Instructions
Once you have downloaded one of the datasets above, you can launch training jobs using the instructions below.
LIBERO: Cosmos policy (predict 2):
export BASE_DATASETS_DIR=/path/to/datasets/
uv run --extra cu128 --group libero --python 3.10 \
torchrun --nproc_per_node=8 --master_port=12341 -m cosmos_policy.scripts.train \
--config=cosmos_policy/config/config.py -- \
experiment="cosmos_predict2_2b_480p_libero" \
trainer.grad_accum_iter=8
Cosmos policy (predict2.5):
export BASE_DATASETS_DIR=/path/to/datasets/
export WANDB_API_KEY=<wandb_api_key>
uv run --extra cu128 --group libero --python 3.10 \
torchrun --nproc_per_node=8 --master_addr=localhost --master_port=12341 -m scripts.train \
--config=cosmos_predict2/_src/predict2/cosmos_policy/config/config.py -- \
experiment=cosmos_predict2p5_2b_480p_libero_no_s3 \
job.group=cosmos_v2_finetune job.name=cosmos_predict2p5_2b_480p_libero_no_s3 \
~dataloader_train.dataloaders dataloader_train.num_workers=4
RoboCasa:
Cosmos policy (predict 2):
export BASE_DATASETS_DIR=/path/to/datasets/
uv run --extra cu128 --group robocasa --python 3.10 \
torchrun --nproc_per_node=8 --master_port=12341 -m cosmos_policy.scripts.train \
--config=cosmos_policy/config/config.py -- \
experiment="cosmos_predict2_2b_480p_robocasa_50_demos_per_task" \
trainer.grad_accum_iter=4
Cosmos policy (predict2.5):
export BASE_DATASETS_DIR=/path/to/datasets/
export WANDB_API_KEY=<wandb_api_key>
uv run --extra cu128 --group robocasa --python 3.10 \
torchrun --nproc_per_node=8 --master_port=12341 -m scripts.train \
--config=cosmos_predict2/_src/predict2/cosmos_policy/config/config.py -- \
experiment=cosmos_predict2p5_2b_480p_robocasa_50_demos_per_task_no_s3 \
job.group=cosmos_v2_finetune \
job.name=cosmos_predict2p5_2b_480p_robocasa_50_demos_per_task_no_s3 \
~dataloader_train.dataloaders dataloader_train.num_workers=4
ALOHA: Cosmos policy (predict 2):
export BASE_DATASETS_DIR=/path/to/datasets/
uv run --extra cu128 --group aloha --python 3.10 \
torchrun --nproc_per_node=8 --master_port=12341 -m cosmos_policy.scripts.train \
--config=cosmos_policy/config/config.py -- \
experiment="cosmos_predict2_2b_480p_aloha_185_demos_4_tasks_mixture_foldshirt15_candiesinbowl45_candyinbag45_eggplantchickenonplate80"
Cosmos policy (predict2.5) was not trained on ALOHA, due to limited access to ALOHA robots.
For reference, below are the training losses that we observed upon convergence. These are rough ballpark numbers you should expect to see when the policy is trained sufficiently. Note that the Cosmos Policy team used multiple nodes instead of gradient accumulation for faster convergence (e.g., for LIBERO and RoboCasa, we used 8 and 4 nodes of 8 H100 GPUs, respectively - no gradient accumulation).
| Loss | Cosmos policy (predict2) | Cosmos policy (predict2.5) |
|---|---|---|
| Action L1 | ~0.010–0.015 | ~0.010–0.015 |
| Future proprio L1 | ~0.007 | ~0.01 |
| Future image latent L1 | ~0.05–0.09 | ~0.05–0.09 |
| Value L1 | ~0.007 | ~0.008 |
Inference with Pretrained Checkpoints
Pretrained Checkpoints
Cosmos policy (predict 2)
| Environment | Checkpoint |
|---|---|
| LIBERO | nvidia/Cosmos-Policy-LIBERO-Predict2-2B |
| RoboCasa | nvidia/Cosmos-Policy-RoboCasa-Predict2-2B |
| ALOHA | nvidia/Cosmos-Policy-ALOHA-Predict2-2B |
Cosmos policy (predict2.5) | Environment | Checkpoint | | --- | --- | | LIBERO | nvidia/Cosmos-Predict2.5-2B | | RoboCasa | nvidia/Cosmos-Predict2.5-2B/ |
Quick Start Example
First, set up a Docker container following the setup instructions earlier in this guide.
Then, inside the Docker container, enter a Python shell via:
Cosmos policy (predict 2):
uv run --extra cu128 --group libero --python 3.10 python.
Cosmos policy (predict2.5):
uv run --extra cu128 --group libero --python 3.10 python.
Then, run the Python code below to generate (1) robot actions, (2) predicted future state (represented by robot proprioception and future image observations), and (3) future state value (expected cumulative rewards):
import pickle
import torch
from PIL import Image
from cosmos_policy.experiments.robot.libero.run_libero_eval import PolicyEvalConfig
from cosmos_policy.experiments.robot.cosmos_utils import (
get_action,
get_model,
load_dataset_stats,
init_t5_text_embeddings_cache,
get_t5_embedding_from_cache,
)
# Instantiate config (see PolicyEvalConfig in cosmos_policy/experiments/robot/libero/run_libero_eval.py for definitions)
cfg = PolicyEvalConfig(
config="cosmos_predict2_2b_480p_libero__inference_only",
ckpt_path="nvidia/Cosmos-Policy-LIBERO-Predict2-2B",
config_file="cosmos_policy/config/config.py",
dataset_stats_path="nvidia/Cosmos-Policy-LIBERO-Predict2-2B/libero_dataset_statistics.json",
t5_text_embeddings_path="nvidia/Cosmos-Policy-LIBERO-Predict2-2B/libero_t5_embeddings.pkl",
use_wrist_image=True,
use_proprio=True,
normalize_proprio=True,
unnormalize_actions=True,
chunk_size=16,
num_open_loop_steps=16,
trained_with_image_aug=True,
use_jpeg_compression=True,
flip_images=True, # Only for LIBERO; images render upside-down
num_denoising_steps_action=5,
num_denoising_steps_future_state=1,
num_denoising_steps_value=1,
)
# Load dataset stats for action/proprio scaling
dataset_stats = load_dataset_stats(cfg.dataset_stats_path)
# Initialize T5 text embeddings cache
init_t5_text_embeddings_cache(cfg.t5_text_embeddings_path)
# Load model
model, cosmos_config = get_model(cfg)
# Load sample observation:
# observation (dict): {
# "primary_image": primary third-person image,
# "wrist_image": wrist-mounted camera image,
# "proprio": robot proprioceptive state,
# }
with open("cosmos_policy/experiments/robot/libero/sample_libero_10_observation.pkl", "rb") as file:
observation = pickle.load(file)
task_description = "put both the alphabet soup and the tomato sauce in the basket"
# Generate robot actions, future state (proprio + images), and value
action_return_dict = get_action(
cfg,
model,
dataset_stats,
observation,
task_description,
num_denoising_steps_action=cfg.num_denoising_steps_action,
generate_future_state_and_value_in_parallel=True,
)
# Print actions
print(f"Generated action chunk: {action_return_dict['actions']}")
# Save future image predictions (third-person image and wrist image)
img_path1, img_path2 = "future_image.png", "future_wrist_image.png"
Image.fromarray(action_return_dict['future_image_predictions']['future_image']).save(img_path1)
Image.fromarray(action_return_dict['future_image_predictions']['future_wrist_image']).save(img_path2)
print(f"Saved future image predictions to:\n\t{img_path1}\n\t{img_path2}")
# Print value
print(f"Generated value: {action_return_dict['value_prediction']}")
For Cosmos policy (predict2.5), please see cosmos_predict2/_src/predict2/cosmos_policy/experiments/robot/libero/run_libero_eval.py
Running Evaluations
Beyond quick start inference, here are the commands you can use to run evaluations with pretrained Cosmos Policy checkpoints and reproduce the results reported in the paper.
LIBERO: We trained Cosmos Policy on four LIBERO task suites altogether in one run: LIBERO-Spatial, LIBERO-Object, LIBERO-Goal, and LIBERO-10 (also called LIBERO-Long). Below is the pretrained checkpoint:
Cosmos policy (predict 2):
Cosmos policy (predict2.5):
To start evaluations with this checkpoint, run the command below, where task_suite_name is one of the following: libero_spatial, libero_object, libero_goal, libero_10. Each will automatically download the checkpoint above. You can set the TRANSFORMERS_CACHE and HF_HOME environment variable to change where the checkpoint files get cached.
Cosmos policy (predict 2):
uv run --extra cu128 --group libero --python 3.10 \
python -m cosmos_policy.experiments.robot.libero.run_libero_eval \
--config cosmos_predict2_2b_480p_libero__inference_only \
--ckpt_path nvidia/Cosmos-Policy-LIBERO-Predict2-2B \
--config_file cosmos_policy/config/config.py \
--use_wrist_image True \
--use_proprio True \
--normalize_proprio True \
--unnormalize_actions True \
--dataset_stats_path nvidia/Cosmos-Policy-LIBERO-Predict2-2B/libero_dataset_statistics.json \
--t5_text_embeddings_path nvidia/Cosmos-Policy-LIBERO-Predict2-2B/libero_t5_embeddings.pkl \
--trained_with_image_aug True \
--chunk_size 16 \
--num_open_loop_steps 16 \
--task_suite_name libero_10 \
--local_log_dir cosmos_policy/experiments/robot/libero/logs/ \
--randomize_seed False \
--data_collection False \
--available_gpus "0,1,2,3,4,5,6,7" \
--seed 195 \
--use_variance_scale False \
--deterministic True \
--run_id_note chkpt45000--5stepAct--seed195--deterministic \
--ar_future_prediction False \
--ar_value_prediction False \
--use_jpeg_compression True \
--flip_images True \
--num_denoising_steps_action 5 \
--num_denoising_steps_future_state 1 \
--num_denoising_steps_value 1
Cosmos policy (predict2.5):
uv run --extra cu128 --group libero --python 3.10 \
python -m cosmos_predict2._src.predict2.cosmos_policy.experiments.robot.libero.run_libero_eval \
--config cosmos_predict2p5_2b_480p_libero__inference_only_no_s3 \
--ckpt_path nvidia/Cosmos-Predict2.5-2B/robot/policy/libero \
--config_file cosmos_predict2/_src/predict2/cosmos_policy/config/config.py \
--use_wrist_image True \
--use_proprio True \
--normalize_proprio True \
--unnormalize_actions True \
--dataset_stats_path nvidia/Cosmos-Policy-LIBERO-Predict2-2B/libero_dataset_statistics.json \
--t5_text_embeddings_path datasets/nvidia/LIBERO-Cosmos-Policy/success_only/reason1_embeddings.pkl \
--text_embeddings_kind reason1 \
--trained_with_image_aug True \
--chunk_size 16 \
--num_open_loop_steps 16 \
--task_suite_name libero_10 \
--local_log_dir cosmos_predict2/_src/predict2/cosmos_policy/experiments/robot/libero/logs/ \
--randomize_seed False \
--data_collection False \
--available_gpus "0,1,2,3,4,5,6,7" \
--seed 195 \
--use_variance_scale False \
--deterministic True \
--run_id_note chkpt45000--5stepAct--seed195--deterministic \
--ar_future_prediction False \
--ar_value_prediction False \
--use_jpeg_compression True \
--flip_images True \
--num_denoising_steps_action 5 \
--num_denoising_steps_future_state 1 \
--num_denoising_steps_value 1 \
--shift 5 \
--data_collection False
Notes:
- The evaluation script will run 500 trials by default (10 tasks x 50 episodes each). You can modify the number of trials per task by setting
--num_trials_per_task. Note that the--seedand--deterministicarguments are important if you want to exactly reproduce the results in the Cosmos Policy paper. We used seeds {195, 196, 197} and--deterministic True. You can change these, but the results may vary slightly (and change every time you run the evaluation). - The evaluation script logs results locally. You can also log results in Weights & Biases by setting
--use_wandb Trueand specifying--wandb_entity <ENTITY>and--wandb_project <PROJECT>. - The results reported in our paper were obtained using Python 3.12.3 (and 3.10.18) and PyTorch 2.7.0 on an NVIDIA H100 GPU, averaged over three random seeds. Note that results may vary slightly if you use a different PyTorch version or different hardware.
RoboCasa:
We trained Cosmos Policy on the RoboCasa benchmark with 24 tasks and 50 demonstrations per task. Below is the pretrained checkpoint: Cosmos policy (predict 2):
- nvidia/Cosmos-Policy-RoboCasa-Predict2-2B Cosmos policy (predict2.5):
- nvidia/Cosmos-Predict2.5-2B
To start evaluations with this checkpoint, run the command below, where task_name can be set to any RoboCasa task (e.g., TurnOffMicrowave). This will automatically download the checkpoint above. You can set the TRANSFORMERS_CACHE and HF_HOME environment variable to change where the checkpoint files get cached.
Cosmos policy (predict 2):
uv run --extra cu128 --group robocasa --python 3.10 \
python -m cosmos_policy.experiments.robot.robocasa.run_robocasa_eval \
--config cosmos_predict2_2b_480p_robocasa_50_demos_per_task__inference \
--ckpt_path nvidia/Cosmos-Policy-RoboCasa-Predict2-2B \
--config_file cosmos_policy/config/config.py \
--use_wrist_image True \
--num_wrist_images 1 \
--use_proprio True \
--normalize_proprio True \
--unnormalize_actions True \
--dataset_stats_path nvidia/Cosmos-Policy-RoboCasa-Predict2-2B/robocasa_dataset_statistics.json \
--t5_text_embeddings_path nvidia/Cosmos-Policy-RoboCasa-Predict2-2B/robocasa_t5_embeddings.pkl \
--trained_with_image_aug True \
--chunk_size 32 \
--num_open_loop_steps 16 \
--task_name TurnOffMicrowave \
--num_trials_per_task 50 \
--run_id_note chkpt45000--5stepAct--seed195--deterministic \
--local_log_dir cosmos_policy/experiments/robot/robocasa/logs/ \
--seed 195 \
--randomize_seed False \
--deterministic True \
--use_variance_scale False \
--use_jpeg_compression True \
--flip_images True \
--num_denoising_steps_action 5 \
--num_denoising_steps_future_state 1 \
--num_denoising_steps_value 1 \
--data_collection False
Cosmos policy (predict2.5):
uv run --extra cu128 --group robocasa --python 3.10 \
python -m cosmos_predict2._src.predict2.cosmos_policy.experiments.robot.robocasa.run_robocasa_eval \
--config cosmos_predict2p5_2b_480p_robocasa_50_demos_per_task__inference \
--ckpt_path nvidia/Cosmos-Predict2.5-2B/robot/policy/robocasa \
--config_file cosmos_predict2/_src/predict2/cosmos_policy/config/config.py\
--use_wrist_image True \
--num_wrist_images 1 \
--use_proprio True \
--normalize_proprio True \
--unnormalize_actions True \
--dataset_stats_path nvidia/Cosmos-Policy-RoboCasa-Predict2-2B/robocasa_dataset_statistics.json \
--t5_text_embeddings_path datasets/nvidia/RoboCasa-Cosmos-Policy/success_only/reason1_embeddings.pkl \
--text_embeddings_kind reason1 \
--trained_with_image_aug True \
--chunk_size 32 \
--num_open_loop_steps 16 \
--task_name OpenSingleDoor \
--num_trials_per_task 50 \
--run_id_note chkpt45000--5stepAct--seed195--deterministic \
--local_log_dir cosmos_predict2/_src/predict2/cosmos_policy/experiments/robot/robocasa/logs/ \
--seed 195 \
--randomize_seed False \
--deterministic True \
--use_variance_scale False \
--use_jpeg_compression True \
--flip_images True \
--num_denoising_steps_action 5 \
--num_denoising_steps_future_state 1 \
--num_denoising_steps_value 1 \
--shift 5 \
--data_collection False
Notes:
- The evaluation script will run 50 trials by default per task. You can modify the number of trials per task by setting
--num_trials_per_task. Note that the--seedand--deterministicarguments are important if you want to exactly reproduce the results in the Cosmos Policy paper. We used seeds {195, 196, 197} and--deterministic True. You can change these, but the results may vary slightly (and change every time you run the evaluation). - The evaluation script logs results locally. You can also log results in Weights & Biases by setting
--use_wandb Trueand specifying--wandb_entity <ENTITY>and--wandb_project <PROJECT>. - The results reported in our paper were obtained using Python 3.12.3 (and 3.10.18) and PyTorch 2.7.0 on an NVIDIA H100 GPU, averaged over three random seeds. Note that results may vary slightly if you use a different PyTorch version or different hardware.
ALOHA:
We omit instructions for ALOHA evaluations, which are more difficult to reproduce than simulated experiments since they require identical hardware setups and environments. However, the Cosmos Policy GitHub repo includes some useful files and instructions that can be used to run the policy on a real ALOHA robot. See the repo here: https://github.com/NVlabs/cosmos-policy
Results
Below are the results achieved by Cosmos Policy, which should be reproducible using the evaluation commands above. We also show sample rollout videos of the policy in action.
LIBERO Benchmark Results
| Method | Spatial SR (%) | Object SR (%) | Goal SR (%) | Long SR (%) | Average SR (%) |
|---|---|---|---|---|---|
| Diffusion Policy | 78.3 | 92.5 | 68.3 | 50.5 | 72.4 |
| Dita | 97.4 | 94.8 | 93.2 | 83.6 | 92.3 |
| \(\pi_{0}\) | 96.8 | 98.8 | 95.8 | 85.2 | 94.2 |
| UVA | -- | -- | -- | 90.0 | -- |
| UniVLA | 96.5 | 96.8 | 95.6 | 92.0 | 95.2 |
| \(\pi_{0.5}\) | 98.8 | 98.2 | 98.0 | 92.4 | 96.9 |
| Video Policy | -- | -- | -- | 94.0 | -- |
| OpenVLA-OFT | 97.6 | 98.4 | 97.9 | 94.5 | 97.1 |
| CogVLA | 98.6 | 98.8 | 96.6 | 95.4 | 97.4 |
| Cosmos policy (predict2) | 98.1 | 100.0 | 98.2 | 97.6 | 98.5 |
| Cosmos policy (predict2.5) | 98.7 | 99.7 | 98.3 | 96.6 | 98.33 |
RoboCasa Benchmark Results
| Method | # Training Demos per Task | Average SR (%) |
|---|---|---|
| GR00T-N1 | 300 | 49.6 |
| UVA | 50 | 50.0 |
| DP-VLA | 3000 | 57.3 |
| GR00T-N1 + DreamGen | 300 (+ 10000 synthetic) | 57.6 |
| GR00T-N1 + DUST | 300 | 58.5 |
| UWM | 1000 | 60.8 |
| \(\pi_{0}\) | 300 | 62.5 |
| GR00T-N1.5 | 300 | 64.1 |
| Video Policy | 300 | 66.0 |
| FLARE | 300 | 66.4 |
| GR00T-N1.5 + HAMLET | 300 | 66.4 |
| Cosmos policy (predict2) (ours) | 50 | 67.1 |
| Cosmos policy (predict2.5) (ours) | 50 | 71.1 |
We observed a substantial performance boost on RoboCasa when upgrading the backbone from Predict2 to Predict2.5—achieving a 4% absolute improvement (from 67.1% to 71.1%) and establishing a new state-of-the-art on the RoboCasa benchmark. This result highlights Predict2.5's enhanced world modeling and generalization capabilities, enabling more robust transfer to diverse robotic manipulation scenarios.
Cosmos Policy achieves state-of-the-art with 6× fewer demonstrations.
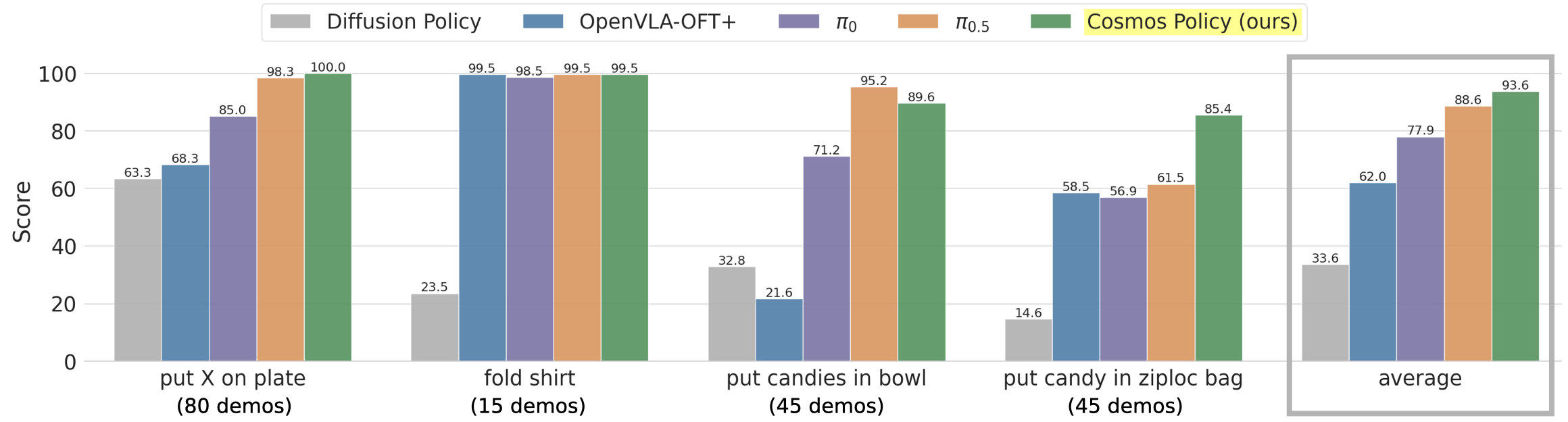
Real-World ALOHA Robot Results
Conclusion
Cosmos Policy demonstrates that video foundation models like Cosmos-Predict2 and Cosmos-Predict 2.5 can be effectively adapted for robotic control through latent frame injection — a simple approach that allows multiple modalities to be modeled in one unified latent diffusion sequence while requiring no architectural modifications. Despite its simplicity, Cosmos Policy achieves state-of-the-art performance on LIBERO (98.5% on Cosmos policy (predict2) and 98.33 on Cosmos policy (predict2.5)), RoboCasa (67.1% on Cosmos policy (predict2) and 71.14 on Cosmos policy (predict2.5)), and ALOHA robot tasks (93.6% on Cosmos policy (predict 2)).
See more details on the Cosmos Policy website: https://research.nvidia.com/labs/dir/cosmos-policy/
Document Information
Publication Date: January 28, 2026
Citation
If you use this recipe or reference this work, please cite it as:
@misc{cosmos_cookbook_cosmos_policy_2026,
title={Cosmos Policy: Fine-Tuning Video Models for Visuomotor Control and Planning},
author={Kim, Moo Jin and Gu, Jinwei},
organization={NVIDIA, Stanford University},
year={2026},
month={January},
howpublished={\url{https://nvidia-cosmos.github.io/cosmos-cookbook/recipes/post_training/predict2/cosmos_policy/post_training.html}},
note={NVIDIA Cosmos Cookbook}
}
Suggested text citation:
Moo Jin Kim, Yuzhu Dong and Jinwei Gu (2026). Cosmos Policy: Fine-Tuning Video Models for Visuomotor Control and Planning. In NVIDIA Cosmos Cookbook. NVIDIA, Stanford University. Accessible at https://nvidia-cosmos.github.io/cosmos-cookbook/recipes/post_training/predict2/cosmos_policy/post_training.html