# Copyright 2026 NVIDIA CORPORATION & AFFILIATES
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
# SPDX-License-Identifier: Apache-2.0
# ---
# jupyter:
# jupytext:
# formats: ipynb,py:percent
# text_representation:
# extension: .py
# format_name: percent
# format_version: '1.3'
# jupytext_version: 1.18.1
# ---
This notebook implements a complete Zero-Shot Video Reasoning Pipeline for industrial safety compliance. It demonstrates how to use NVIDIA Cosmos Reason 2, a multimodal Video Language Model (VLM), to act as an automated safety inspector in challenging "brownfield" environments.
Unlike modern, pristine factories, "classical" warehouses often feature faded floor markings, irregular lighting, and worn infrastructure. Standard computer vision models often struggle here, confusing environmental noise with hazards. In this workflow, we solve this by using Context-Aware Prompt Engineering to force the model to ignore the background and focus strictly on specific visual ground truths.
2. Load dataset and copy the first video to assets/sample.mp4 - Testing the installation¶
import pathlib
import shutil
# 2. Load dataset and copy the first video to assets/sample.mp4
import fiftyone as fo
import fiftyone.utils.huggingface as fouh
ROOT = pathlib.Path.cwd()
ASSETS = ROOT / "assets"
ASSETS.mkdir(exist_ok=True)
# NOTE: omit overwrite=True so existing annotations are preserved
dataset = fouh.load_from_hub("pjramg/Safe_Unsafe_Test", persistent=True)
# dataset = fo.load_dataset("pjramg/Safe_Unsafe_Test") #
sample = dataset.first()
if sample is None:
raise RuntimeError("Dataset is empty")
if sample.media_type != "video":
raise RuntimeError(
f"First sample is not a video (media_type={sample.media_type}). Use --images instead."
)
dst = ASSETS / "sample.mp4"
shutil.copy2(sample.filepath, dst)
print("Reference video copied to:", dst)
3. CUDA / environment sanity check¶
# 3. CUDA / environment sanity check
import os
import torch
print("CUDA available:", torch.cuda.is_available())
if torch.cuda.is_available():
print("CUDA device count:", torch.cuda.device_count())
print("Current device index:", torch.cuda.current_device())
print("Device name:", torch.cuda.get_device_name(0))
print("CUDA_VISIBLE_DEVICES:", os.environ.get("CUDA_VISIBLE_DEVICES"))
4. Run the default inference_sample.py file¶
Be sure you are addressing the right sample.mp4 file, check the inference_sample.py file in the Cosmos Reason 2 repository. Make modification to the prompt if needed. This script assumes Cosmos Reason 2 is installed following the setup in the Cosmos Reason 2 repo.
!python ../scripts/inference_sample.py
5. Initialize the model and create the prompts¶
#!/usr/bin/env -S uv run --script
import json
import warnings
from pathlib import Path
import transformers
warnings.filterwarnings("ignore")
# --- MODEL INITIALIZATION ---
def load_model():
model_name = "nvidia/Cosmos-Reason2-2B"
model = transformers.Qwen3VLForConditionalGeneration.from_pretrained(
model_name, dtype=torch.float16, device_map="auto", attn_implementation="sdpa"
)
processor = transformers.Qwen3VLProcessor.from_pretrained(model_name)
# Pixel token limits
PIXELS_PER_TOKEN = 32**2
min_vision_tokens, max_vision_tokens = 256, 8192
processor.image_processor.size = processor.video_processor.size = {
"shortest_edge": min_vision_tokens * PIXELS_PER_TOKEN,
"longest_edge": max_vision_tokens * PIXELS_PER_TOKEN,
}
return model, processor
# --- PROMPTS ---
SYSTEM_INSTRUCTIONS = """
You are an expert Industrial Safety Inspector monitoring a manufacturing facility.
Your goal is to classify the video into EXACTLY ONE of the 8 classes defined below.
CRITICAL NEGATIVE CONSTRAINTS (What to IGNORE):
1. IGNORE SITTING WORKERS:
- If a person is SITTING at a machine board working, this is NOT an intervention class. Ignore them.
- If a person is SITTING driving a forklift, the driver is NOT the class. Focus only on the LOAD carried.
2. IGNORE BACKGROUND:
- The facility is old. Do not report hazards based on faded floor markings or unpainted areas.
3. SINGLE OUTPUT:
- Even if multiple things happen, choose the MOST PROMINENT behavior.
- Prioritize UNSAFE behaviors over SAFE behaviors if both are present.
"""
USER_PROMPT_CONTENT = """
Analyze the video and output a JSON object. You MUST select the class ID and Label EXACTLY from the table below.
STRICT CLASSIFICATION TABLE (Use these exact IDs and Labels):
| ID | Label | Definition (Ground Truth) | Hazard Status |
| :--- | :--- | :--- | :--- |
| 0 | Safe Walkway Violation | Worker walks OUTSIDE the designated Green Path. | TRUE (Unsafe) |
| 4 | Safe Walkway | Worker walks INSIDE the designated Green Path. | FALSE (Safe) |
| 1 | Unauthorized Intervention | Worker interacts with machine board WITHOUT a green vest. | TRUE (Unsafe) |
| 5 | Authorized Intervention | Worker interacts with machine board WITH a green vest. | FALSE (Safe) |
| 2 | Opened Panel Cover | Machine panel cover is left OPEN after intervention. | TRUE (Unsafe) |
| 6 | Closed Panel Cover | Machine panel cover is CLOSED after intervention. | FALSE (Safe) |
| 3 | Carrying Overload with Forklift | Forklift carries 3 OR MORE blocks. | TRUE (Unsafe) |
| 7 | Safe Carrying | Forklift carries 2 OR FEWER blocks. | FALSE (Safe) |
INSTRUCTIONS:
1. Identify the behavior in the video.
2. Match it to one row in the table above.
3. Output the exact "ID" and "Label" from that row. Do not invent new labels like "safe and compliant".
OUTPUT FORMAT:
{
"prediction_class_id": [Integer from Table],
"prediction_label": "[Exact String from Table]",
"video_description": "[Concise description of the observed action]",
"hazard_detection": {
"is_hazardous": [true/false based on the Hazard Status column],
"temporal_segment": "[Start Time - End Time] or null"
}
}
"""
6. Reload the dataset / Prepare inputs / Run Cosmos Reason 2 in the whole dataset¶
# 1. Load the FiftyOne Dataset
# Replace "your_dataset_name" with your actual dataset name
dataset = fo.load_dataset("pjramg/Safe_Unsafe_Test")
# 2. Setup Model
model, processor = load_model()
transformers.set_seed(0)
print(f"Processing {len(dataset)} videos...")
# 3. Iterate through FiftyOne Samples
# Use progress_bar to track status
for sample in dataset.iter_samples(progress=True):
video_path = sample.filepath
# Prepare inputs
conversation = [
{"role": "system", "content": [{"type": "text", "text": SYSTEM_INSTRUCTIONS}]},
{
"role": "user",
"content": [
{"type": "video", "video": video_path},
{"type": "text", "text": USER_PROMPT_CONTENT},
],
},
]
try:
inputs = processor.apply_chat_template(
conversation,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt",
fps=4, # Set FPS here
).to(model.device)
# Inference
generated_ids = model.generate(**inputs, max_new_tokens=1024)
generated_ids_trimmed = [
out_ids[len(in_ids) :]
for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed,
skip_special_tokens=True,
clean_up_tokenization_spaces=False,
)[0]
# 4. Parse and Save to FiftyOne
# Cosmos-Reason2 usually outputs clean JSON, but we wrap in try/except
try:
# Cleaning markdown blocks if model returns ```json ... ```
clean_json = output_text.strip().replace("```json", "").replace("```", "")
json_data = json.loads(clean_json)
# Store as a custom field "cosmos_analysis"
sample["cosmos_analysis"] = json_data
# Optional: Also add the label as a top-level classification for easy filtering
sample["safety_label"] = fo.Classification(
label=json_data.get("prediction_label"),
)
sample.save()
except Exception as e:
print(f"JSON Parsing failed for {video_path}: {e}")
sample["cosmos_error"] = str(output_text)
sample.save()
except Exception as e:
print(f"Inference failed for {video_path}: {e}")
print("Processing complete. Launching App...")
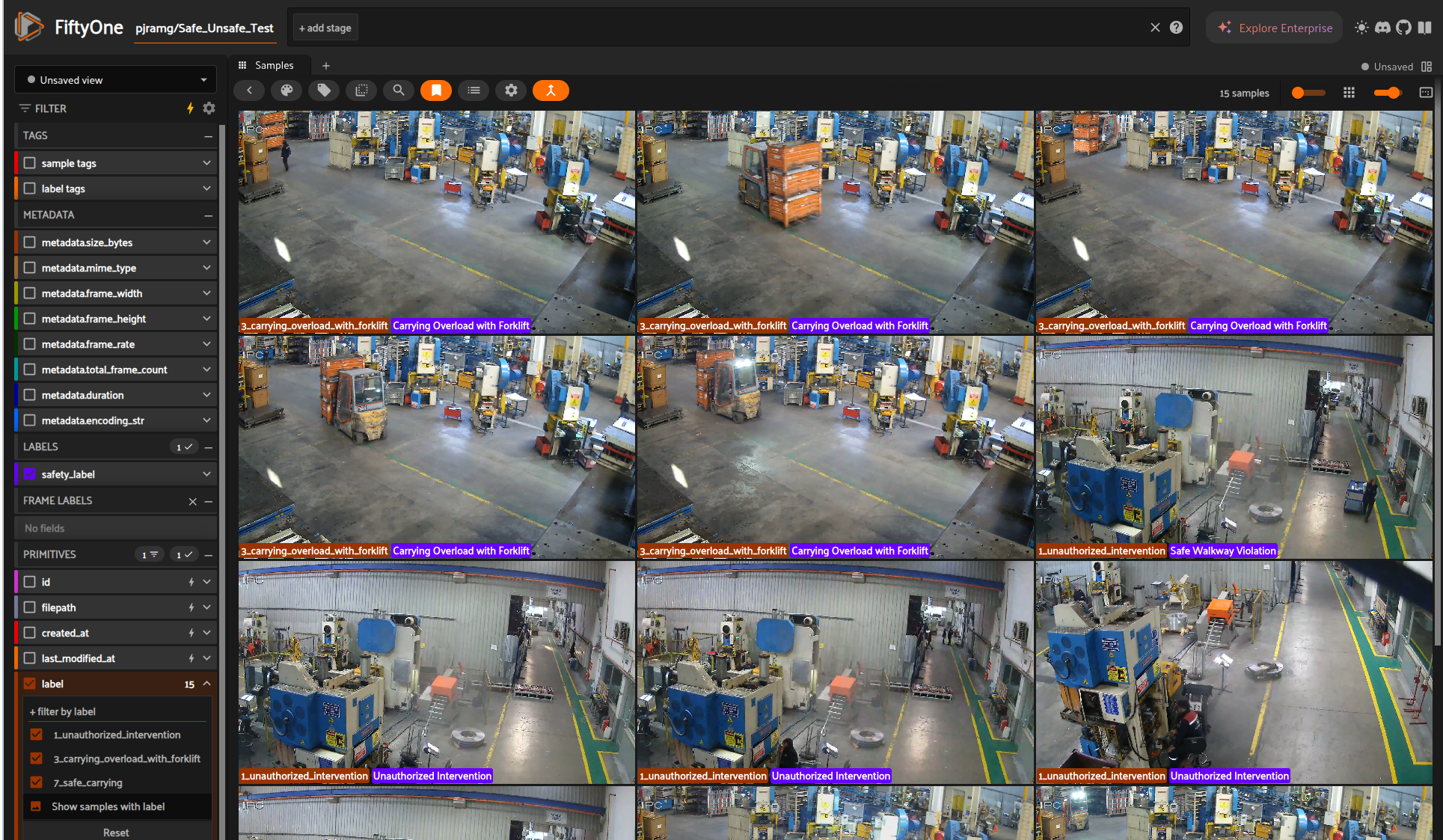
7. Visualize the results in FiftyOne, compare results with Ground Truth and make adjustments if needed.¶
session = fo.launch_app(dataset)
session.wait()